 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal 3D Object Detection via Modality-Agnostic Decoding and Proximity-based Modality Ensemble
Jul 27, 2024Recent advancements in 3D object detection have benefited from multi-modal information from the multi-view cameras and LiDAR sensors. However, the inherent disparities between the modalities pose substantial challenges. We observe that existing multi-modal 3D object detection methods heavily rely on the LiDAR sensor, treating the camera as an auxiliary modality for augmenting semantic details. This often leads to not only underutilization of camera data but also significant performance degradation in scenarios where LiDAR data is unavailable. Additionally, existing fusion methods overlook the detrimental impact of sensor noise induced by environmental changes, on detection performance. In this paper, we propose MEFormer to address the LiDAR over-reliance problem by harnessing critical information for 3D object detection from every available modality while concurrently safeguarding against corrupted signals during the fusion process. Specifically, we introduce Modality Agnostic Decoding (MOAD) that extracts geometric and semantic features with a shared transformer decoder regardless of input modalities and provides promising improvement with a single modality as well as multi-modality. Additionally, our Proximity-based Modality Ensemble (PME) module adaptively utilizes the strengths of each modality depending on the environment while mitigating the effects of a noisy sensor. Our MEFormer achieves state-of-the-art performance of 73.9% NDS and 71.5% mAP in the nuScenes validation set. Extensive analyses validate that our MEFormer improves robustness against challenging conditions such as sensor malfunctions or environmental changes. The source code is available at https://github.com/hanchaa/MEFormer
Semantic-Aware Implicit Template Learning via Part Deformation Consistency
Aug 23, 2023

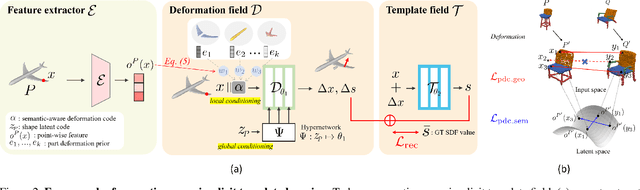

Learning implicit templates as neural fields has recently shown impressive performance in unsupervised shape correspondence. Despite the success, we observe current approaches, which solely rely on geometric information, often learn suboptimal deformation across generic object shapes, which have high structural variability. In this paper, we highlight the importance of part deformation consistency and propose a semantic-aware implicit template learning framework to enable semantically plausible deformation. By leveraging semantic prior from a self-supervised feature extractor, we suggest local conditioning with novel semantic-aware deformation code and deformation consistency regularizations regarding part deformation, global deformation, and global scaling. Our extensive experiments demonstrate the superiority of the proposed method over baselines in various tasks: keypoint transfer, part label transfer, and texture transfer. More interestingly, our framework shows a larger performance gain under more challenging settings. We also provide qualitative analyses to validate the effectiveness of semantic-aware deformation. The code is available at https://github.com/mlvlab/PDC.