 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information Theoretic Metric for Evaluating Unlearning Models
Paper and Code
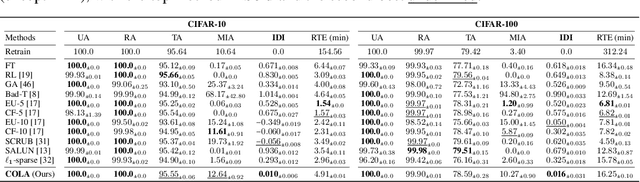
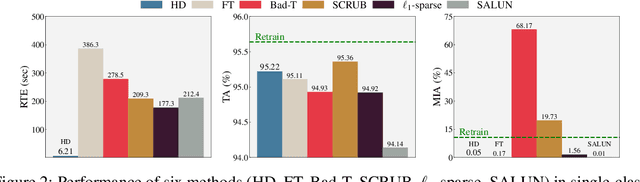
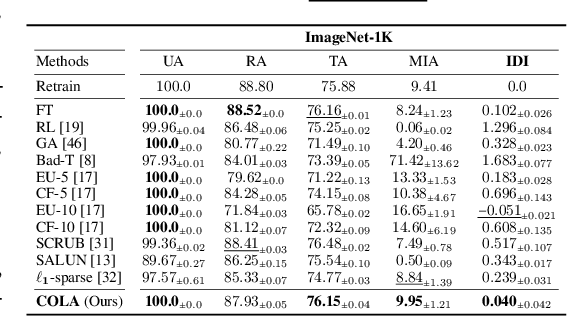
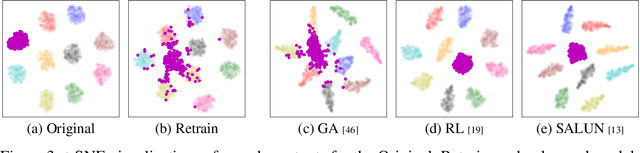
Machine unlearning (MU) addresses privacy concerns by removing information of `forgetting data' samples from trained models. Typically, evaluating MU methods involves comparing unlearned models to those retrained from scratch without forgetting data, using metrics such as membership inference attacks (MIA) and accuracy measurements. These evaluations implicitly assume that if the output logits of the unlearned and retrained models are similar, the unlearned model has successfully forgotten the data. Here, we challenge if this assumption is valid. In particular, we conduct a simple experiment of training only the last layer of a given original model using a novel masked-distillation technique while keeping the rest fixed. Surprisingly, simply altering the last layer yields favorable outcomes in the existing evaluation metrics, while the model does not successfully unlearn the samples or classes. For better evaluating the MU methods, we propose a metric that quantifies the residual information about forgetting data samples in intermediate features using mutual information, called information difference index or IDI for short. The IDI provides a comprehensive evaluation of MU methods by efficiently analyzing the internal structure of DNNs. Our metric is scalable to large datasets and adaptable to various model architectures. Additionally, we present COLapse-and-Align (COLA), a simple contrastive-based method that effectively unlearns intermediate features.