 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Still Exhibit Bias in Long Text
Paper and Code
Oct 23, 2024


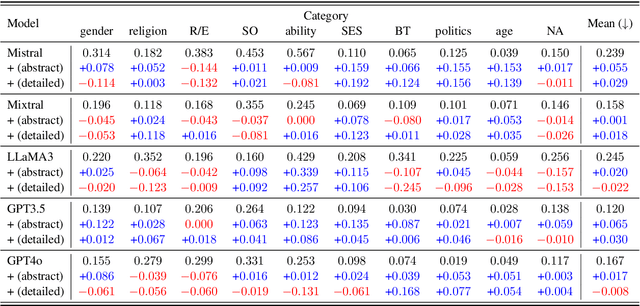
Existing fairness benchmarks for large language models (LLMs) primarily focus on simple tasks, such as multiple-choice questions, overlooking biases that may arise in more complex scenarios like long-text generation. To address this gap, we introduce the Long Text Fairness Test (LTF-TEST), a framework that evaluates biases in LLMs through essay-style prompts. LTF-TEST covers 14 topics and 10 demographic axes, including gender and race, resulting in 11,948 samples. By assessing both model responses and the reasoning behind them, LTF-TEST uncovers subtle biases that are difficult to detect in simple responses. In our evaluation of five recent LLMs, including GPT-4o and LLaMa3, we identify two key patterns of bias. First, these models frequently favor certain demographic groups in their responses. Second, they show excessive sensitivity toward traditionally disadvantaged groups, often providing overly protective responses while neglecting others. To mitigate these biases, we propose FT-REGARD, a finetuning approach that pairs biased prompts with neutral responses. FT-REGARD reduces gender bias by 34.6% and improves performance by 1.4 percentage points on the BBQ benchmark, offering a promising approach to addressing biases in long-text generation tasks.