 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Paper and Code

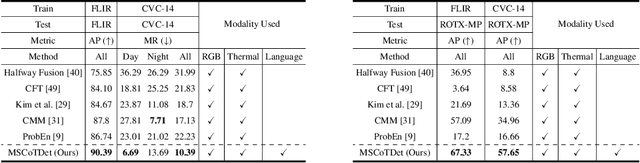

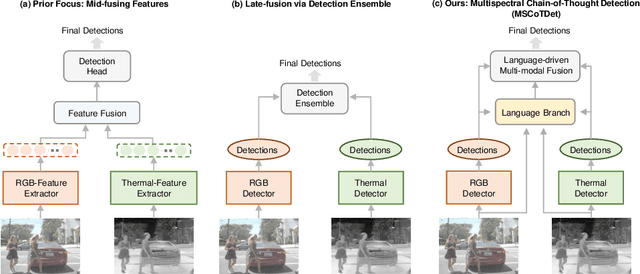
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in obvious cases, especially due to the modality bias learned from statistically biased datasets. From these problems, we anticipate that maybe understanding the complementary information itself is difficult to achieve from vision-only models. Accordingly, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework, which incorporates Large Language Models (LLMs) to understand the complementary information at the semantic level and further enhance the fusion process. Specifically, we generate text descriptions of the pedestrian in each RGB and thermal modality and design a Multispectral Chain-of-Thought (MSCoT) prompting, which models a step-by-step process to facilitate cross-modal reasoning at the semantic level and perform accurate detection. Moreover, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing vision-driven and language-driven detections. Extensive experiments validate that MSCoTDet improves multispectral pedestrian detection.