 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
C-RADIOv4 (Tech Report)
Jan 24, 2026By leveraging multi-teacher distillation, agglomerative vision backbones provide a unified student model that retains and improves the distinct capabilities of multiple teachers. In this tech report, we describe the most recent release of the C-RADIO family of models, C-RADIOv4, which builds upon AM-RADIO/RADIOv2.5 in design, offering strong improvements on key downstream tasks at the same computational complexity. We release -SO400M (412M params), and -H (631M) model variants, both trained with an updated set of teachers: SigLIP2, DINOv3, and SAM3. In addition to improvements on core metrics and new capabilities from imitating SAM3, the C-RADIOv4 model family further improves any-resolution support, brings back the ViTDet option for drastically enhanced efficiency at high-resolution, and comes with a permissive license.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
FeatSharp: Your Vision Model Features, Sharper
Feb 22, 2025The feature maps of vision encoders are fundamental to myriad modern AI tasks, ranging from core perception algorithms (e.g. semantic segmentation, object detection, depth perception, etc.) to modern multimodal understanding in vision-language models (VLMs). Currently, in computer vision, the frontier of general purpose vision backbones are Vision Transformers (ViT), typically trained using contrastive loss (e.g. CLIP). A key problem with most off-the-shelf ViTs, particularly CLIP, is that these models are inflexibly low resolution. Most run at 224x224px, while the "high resolution" versions are around 378-448px, but still inflexible. We introduce a novel method to coherently and cheaply upsample the feature maps of low-res vision encoders while picking up on fine-grained details that would otherwise be lost due to resolution. We demonstrate the effectiveness of this approach on core perception tasks as well as within agglomerative model (RADIO) training as a way of providing richer targets for distillation.
RADIO Amplified: Improved Baselines for Agglomerative Vision Foundation Models
Dec 10, 2024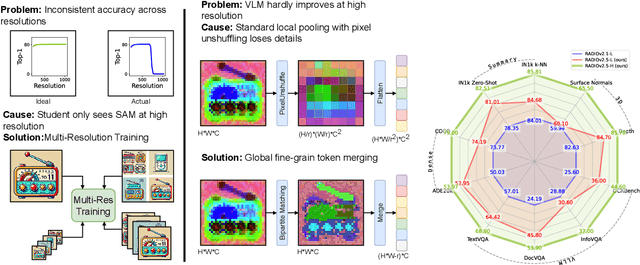



Agglomerative models have recently emerged as a powerful approach to training vision foundation models, leveraging multi-teacher distillation from existing models such as CLIP, DINO, and SAM. This strategy enables the efficient creation of robust models, combining the strengths of individual teachers while significantly reducing computational and resource demands. In this paper, we thoroughly analyze state-of-the-art agglomerative models, identifying critical challenges including resolution mode shifts, teacher imbalance, idiosyncratic teacher artifacts, and an excessive number of output tokens. To address these issues, we propose several novel solutions: multi-resolution training, mosaic augmentation, and improved balancing of teacher loss functions. Specifically, in the context of Vision Language Models, we introduce a token compression technique to maintain high-resolution information within a fixed token count. We release our top-performing models, available in multiple scales (-B, -L, -H, and -g), alongside inference code and pretrained weights.
PHI-S: Distribution Balancing for Label-Free Multi-Teacher Distillation
Oct 02, 2024



Various visual foundation models have distinct strengths and weaknesses, both of which can be improved through heterogeneous multi-teacher knowledge distillation without labels, termed "agglomerative models." We build upon this body of work by studying the effect of the teachers' activation statistics, particularly the impact of the loss function on the resulting student model quality. We explore a standard toolkit of statistical normalization techniques to better align the different distributions and assess their effects. Further, we examine the impact on downstream teacher-matching metrics, which motivates the use of Hadamard matrices. With these matrices, we demonstrate useful properties, showing how they can be used for isotropic standardization, where each dimension of a multivariate distribution is standardized using the same scale. We call this technique "PHI Standardization" (PHI-S) and empirically demonstrate that it produces the best student model across the suite of methods studied.
AM-RADIO: Agglomerative Model -- Reduce All Domains Into One
Dec 21, 2023A handful of visual foundation models (VFMs) have recently emerged as the backbones for numerous downstream tasks. VFMs like CLIP, DINOv2, SAM are trained with distinct objectives, exhibiting unique characteristics for various downstream tasks. We find that despite their conceptual differences, these models can be effectively merged into a unified model through multi-teacher distillation. We name this approach AM-RADIO (Agglomerative Model -- Reduce All Domains Into One). This integrative approach not only surpasses the performance of individual teacher models but also amalgamates their distinctive features, such as zero-shot vision-language comprehension, detailed pixel-level understanding, and open vocabulary segmentation capabilities. In pursuit of the most hardware-efficient backbone, we evaluated numerous architectures in our multi-teacher distillation pipeline using the same training recipe. This led to the development of a novel architecture (E-RADIO) that exceeds the performance of its predecessors and is at least 7x faster than the teacher models. Our comprehensive benchmarking process covers downstream tasks including ImageNet classification, ADE20k semantic segmentation, COCO object detection and LLaVa-1.5 framework. Code: https://github.com/NVlabs/RADIO