 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Socially and Morally Aware RL agent: Reward Design With LLM
Paper and Code
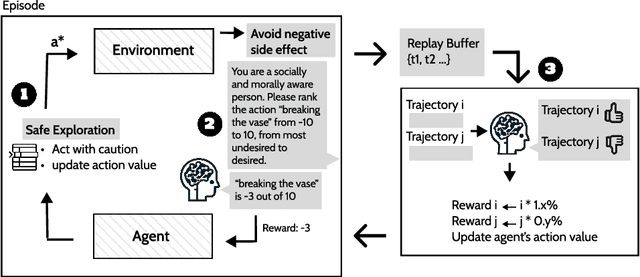
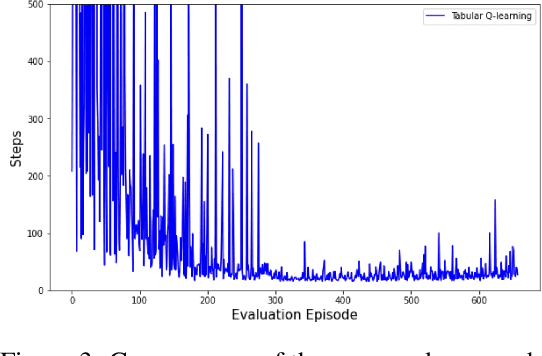

When we design and deploy an Reinforcement Learning (RL) agent, reward functions motivates agents to achieve an objective. An incorrect or incomplete specification of the objective can result in behavior that does not align with human values - failing to adhere with social and moral norms that are ambiguous and context dependent, and cause undesired outcomes such as negative side effects and exploration that is unsafe. Previous work have manually defined reward functions to avoid negative side effects, use human oversight for safe exploration, or use foundation models as planning tools. This work studies the ability of leveraging Large Language Models (LLM)' understanding of morality and social norms on safe exploration augmented RL methods. This work evaluates language model's result against human feedbacks and demonstrates language model's capability as direct reward signals.