 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Interpretable Logic Rules from Graph Neural Networks
Mar 25, 2025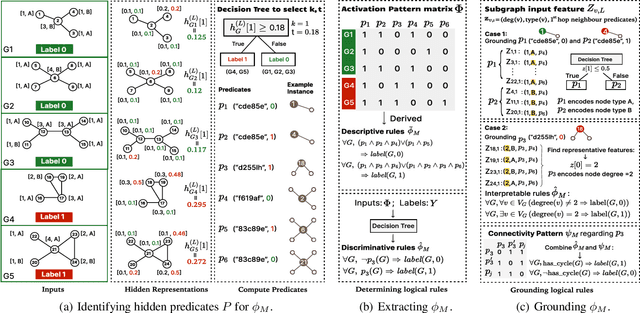

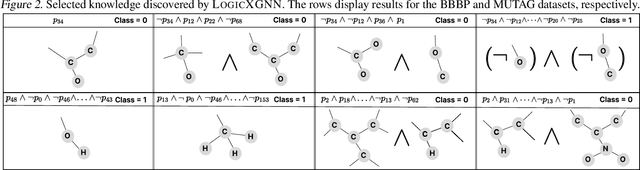
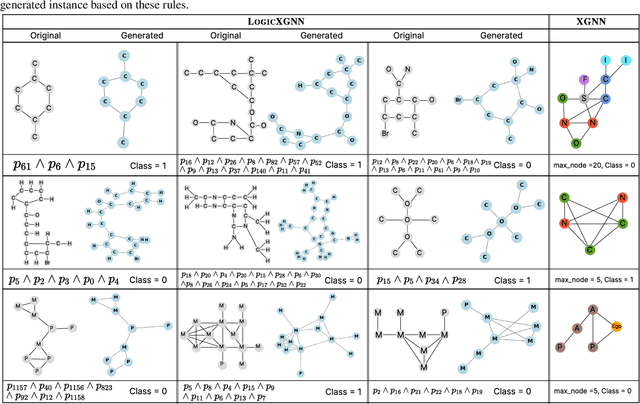
Graph neural networks (GNNs) operate over both input feature spaces and combinatorial graph structures, making it challenging to understand the rationale behind their predictions. As GNNs gain widespread popularity and demonstrate success across various domains, such as drug discovery, studying their interpretability has become a critical task. To address this, many explainability methods have been proposed, with recent efforts shifting from instance-specific explanations to global concept-based explainability. However, these approaches face several limitations, such as relying on predefined concepts and explaining only a limited set of patterns. To address this, we propose a novel framework, LOGICXGNN, for extracting interpretable logic rules from GNNs. LOGICXGNN is model-agnostic, efficient, and data-driven, eliminating the need for predefined concepts. More importantly, it can serve as a rule-based classifier and even outperform the original neural models. Its interpretability facilitates knowledge discovery, as demonstrated by its ability to extract detailed and accurate chemistry knowledge that is often overlooked by existing methods. Another key advantage of LOGICXGNN is its ability to generate new graph instances in a controlled and transparent manner, offering significant potential for applications such as drug design. We empirically demonstrate these merits through experiments on real-world datasets such as MUTAG and BBBP.
Learning Interpretable Logic Rules from Deep Vision Models
Mar 13, 2025

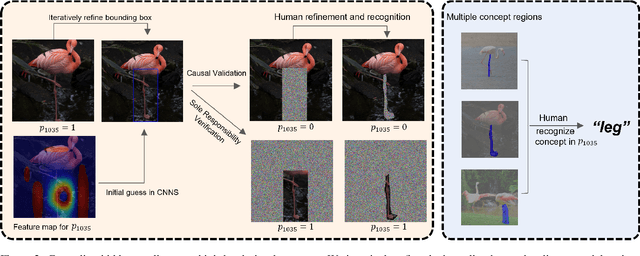

We propose a general framework called VisionLogic to extract interpretable logic rules from deep vision models, with a focus on image classification tasks. Given any deep vision model that uses a fully connected layer as the output head, VisionLogic transforms neurons in the last layer into predicates and grounds them into vision concepts using causal validation. In this way, VisionLogic can provide local explanations for single images and global explanations for specific classes in the form of logic rules. Compared to existing interpretable visualization tools such as saliency maps, VisionLogic addresses several key challenges, including the lack of causal explanations, overconfidence in visualizations, and ambiguity in interpretation. VisionLogic also facilitates the study of visual concepts encoded by predicates, particularly how they behave under perturbation -- an area that remains underexplored in the field of hidden semantics. Apart from providing better visual explanations and insights into the visual concepts learned by the model, we show that VisionLogic retains most of the neural network's discriminative power in an interpretable and transparent manner. We envision it as a bridge between complex model behavior and human-understandable explanations, providing trustworthy and actionable insights for real-world applications.
HetHub: A Heterogeneous distributed hybrid training system for large-scale models
May 25, 2024The development of large-scale models relies on a vast number of computing resources. For example, the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs for its training. It is a challenge to build a large-scale cluster with a type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism support on heterogeneous GPU-accelerators for large-scale models. It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic hybrid parallel module to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six different combinations of heterogeneous GPU-accelerators and the optimal performance of heterogeneous GPU-accelerators has achieved at least 90% of the theoretical upper bound performance of homogeneous GPU-accelerators.
Learning Minimal NAP Specifications for Neural Network Verification
Apr 06, 2024



Specifications play a crucial role in neural network verification. They define the precise input regions we aim to verify, typically represented as L-infinity norm balls. While recent research suggests using neural activation patterns (NAPs) as specifications for verifying unseen test set data, it focuses on computing the most refined NAPs, often limited to very small regions in the input space. In this paper, we study the following problem: Given a neural network, find a minimal (coarsest) NAP that is sufficient for formal verification of the network's robustness. Finding the minimal NAP specification not only expands verifiable bounds but also provides insights into which neurons contribute to the model's robustness. To address this problem, we propose several exact and approximate approaches. Our exact approaches leverage the verification tool to find minimal NAP specifications in either a deterministic or statistical manner. Whereas the approximate methods efficiently estimate minimal NAPs using adversarial examples and local gradients, without making calls to the verification tool. This allows us to inspect potential causal links between neurons and the robustness of state-of-the-art neural networks, a task for which existing verification frameworks fail to scale. Our experimental results suggest that minimal NAP specifications require much smaller fractions of neurons compared to the most refined NAP specifications, yet they can significantly expand the verifiable boundaries to several orders of magnitude larger.
Scalar Invariant Networks with Zero Bias
Nov 15, 2022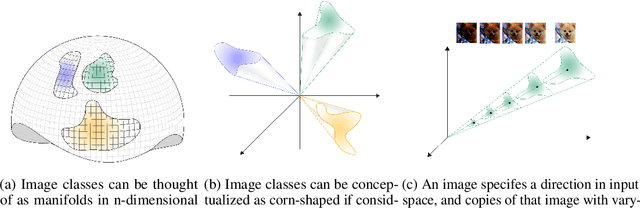
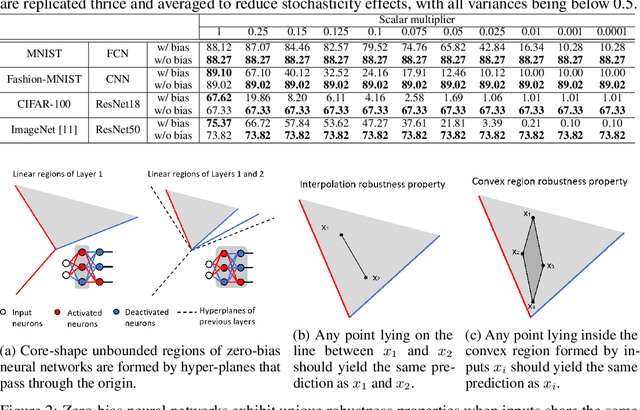

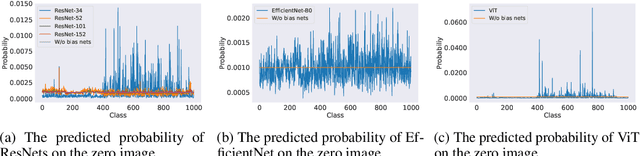
Just like weights, bias terms are the learnable parameters of many popular machine learning models, including neural networks. Biases are believed to effectively increase the representational power of neural networks to solve a wide range of tasks in computer vision. However, we argue that if we consider the intrinsic distribution of images in the input space as well as some desired properties a model should have from the first principles, biases can be completely ignored in addressing many image-related tasks, such as image classification. Our observation indicates that zero-bias neural networks could perform comparably to neural networks with bias at least on practical image classification tasks. In addition, we prove that zero-bias neural networks possess a nice property called scalar (multiplication) invariance, which has great potential in learning and understanding images captured under poor illumination conditions. We then extend scalar invariance to more general cases that allow us to verify certain convex regions of the input space. Our experimental results show that zero-bias models could outperform the state-of-art models by a very large margin (over 60%) when predicting images under a low illumination condition (multiplying a scalar of 0.01); while achieving the same-level performance as normal models.
Novice Type Error Diagnosis with Natural Language Models
Oct 07, 2022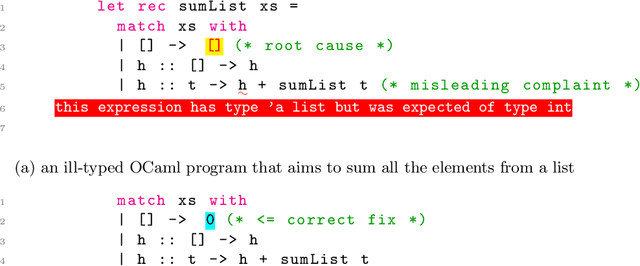

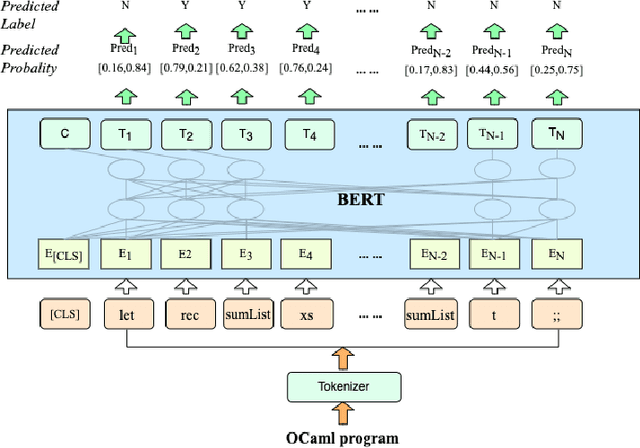
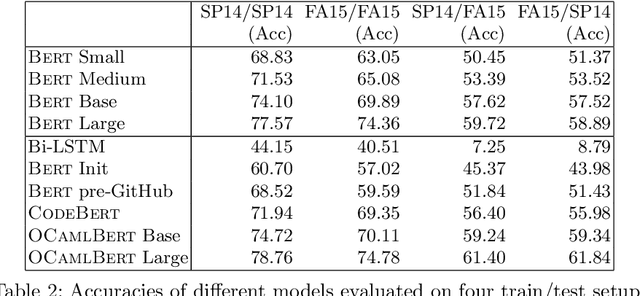
Strong static type systems help programmers eliminate many errors without much burden of supplying type annotations. However, this flexibility makes it highly non-trivial to diagnose ill-typed programs, especially for novice programmers. Compared to classic constraint solving and optimization-based approaches, the data-driven approach has shown great promise in identifying the root causes of type errors with higher accuracy. Instead of relying on hand-engineered features, this work explores natural language models for type error localization, which can be trained in an end-to-end fashion without requiring any features. We demonstrate that, for novice type error diagnosis, the language model-based approach significantly outperforms the previous state-of-the-art data-driven approach. Specifically, our model could predict type errors correctly 62% of the time, outperforming the state-of-the-art Nate's data-driven model by 11%, in a more rigorous accuracy metric. Furthermore, we also apply structural probes to explain the performance difference between different language models.