 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT Pass An Introductory Level Functional Language Programming Course?
May 04, 2023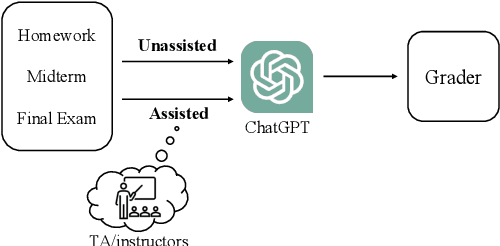
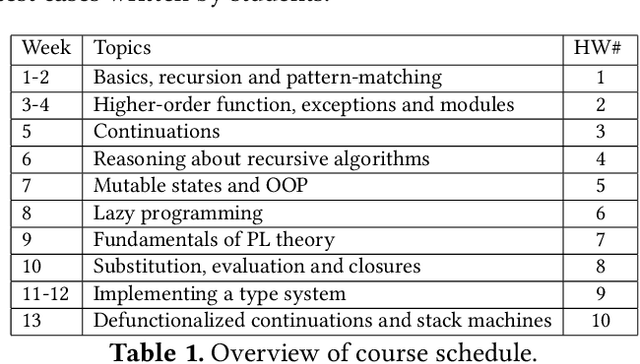
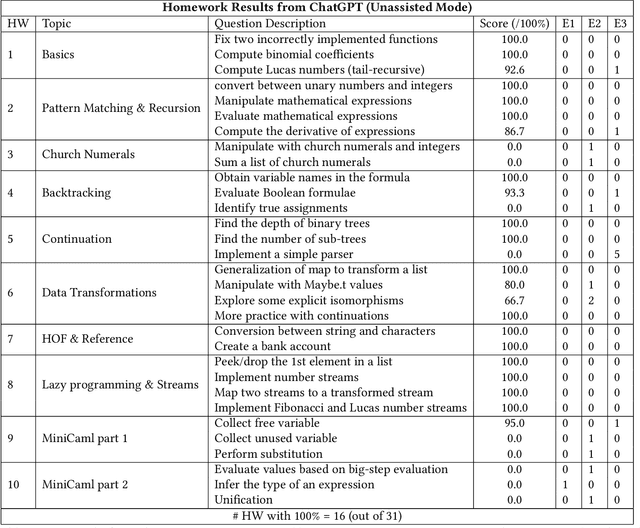
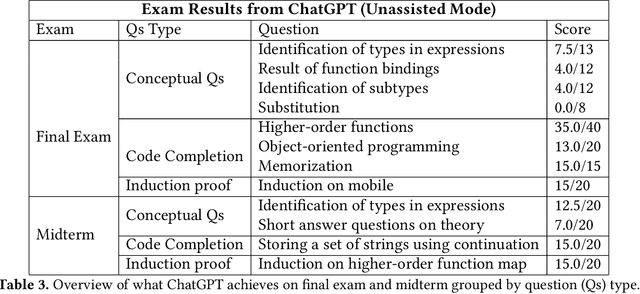
The recent introduction of ChatGPT has drawn significant attention from both industry and academia due to its impressive capabilities in solving a diverse range of tasks, including language translation, text summarization, and computer programming. Its capability for writing, modifying, and even correcting code together with its ease of use and access is already dramatically impacting computer science education. This paper aims to explore how well ChatGPT can perform in an introductory-level functional language programming course. In our systematic evaluation, we treated ChatGPT as one of our students and demonstrated that it can achieve a grade B- and its rank in the class is 155 out of 314 students overall. Our comprehensive evaluation provides valuable insights into ChatGPT's impact from both student and instructor perspectives. Additionally, we identify several potential benefits that ChatGPT can offer to both groups. Overall, we believe that this study significantly clarifies and advances our understanding of ChatGPT's capabilities and potential impact on computer science education.
Novice Type Error Diagnosis with Natural Language Models
Oct 07, 2022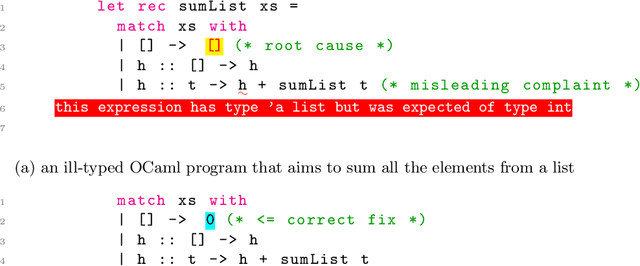

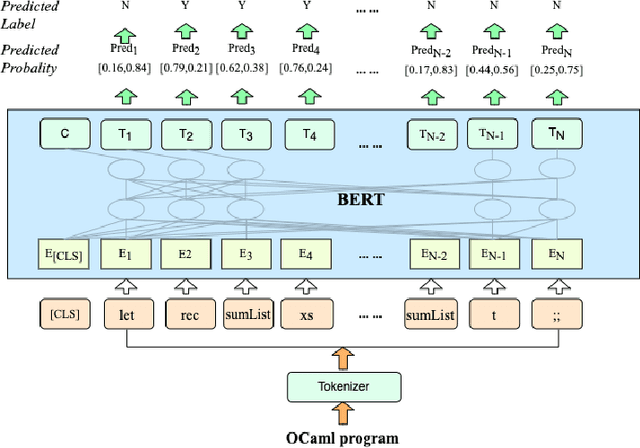
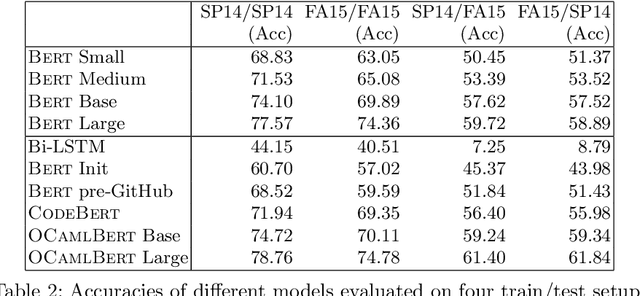
Strong static type systems help programmers eliminate many errors without much burden of supplying type annotations. However, this flexibility makes it highly non-trivial to diagnose ill-typed programs, especially for novice programmers. Compared to classic constraint solving and optimization-based approaches, the data-driven approach has shown great promise in identifying the root causes of type errors with higher accuracy. Instead of relying on hand-engineered features, this work explores natural language models for type error localization, which can be trained in an end-to-end fashion without requiring any features. We demonstrate that, for novice type error diagnosis, the language model-based approach significantly outperforms the previous state-of-the-art data-driven approach. Specifically, our model could predict type errors correctly 62% of the time, outperforming the state-of-the-art Nate's data-driven model by 11%, in a more rigorous accuracy metric. Furthermore, we also apply structural probes to explain the performance difference between different language models.