 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalar Invariant Networks with Zero Bias
Paper and Code
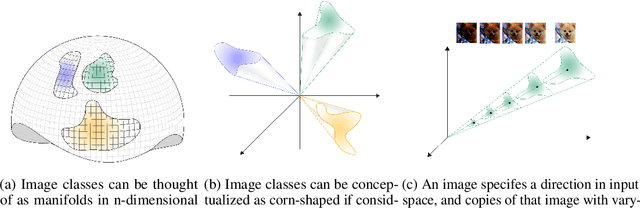
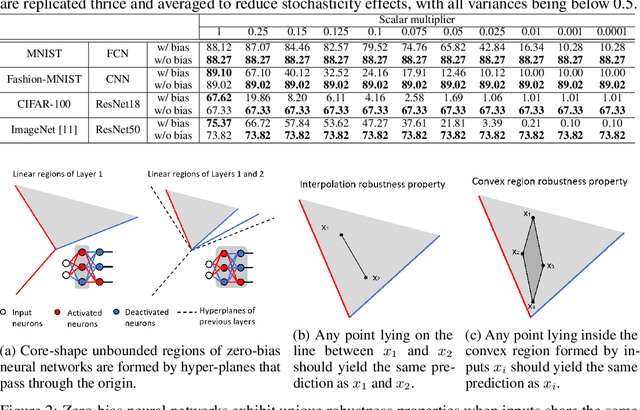

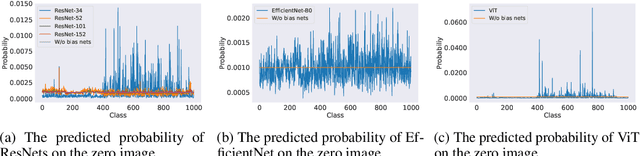
Just like weights, bias terms are the learnable parameters of many popular machine learning models, including neural networks. Biases are believed to effectively increase the representational power of neural networks to solve a wide range of tasks in computer vision. However, we argue that if we consider the intrinsic distribution of images in the input space as well as some desired properties a model should have from the first principles, biases can be completely ignored in addressing many image-related tasks, such as image classification. Our observation indicates that zero-bias neural networks could perform comparably to neural networks with bias at least on practical image classification tasks. In addition, we prove that zero-bias neural networks possess a nice property called scalar (multiplication) invariance, which has great potential in learning and understanding images captured under poor illumination conditions. We then extend scalar invariance to more general cases that allow us to verify certain convex regions of the input space. Our experimental results show that zero-bias models could outperform the state-of-art models by a very large margin (over 60%) when predicting images under a low illumination condition (multiplying a scalar of 0.01); while achieving the same-level performance as normal models.