 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Interpretable Logic Rules from Deep Vision Models
Paper and Code
Mar 13, 2025

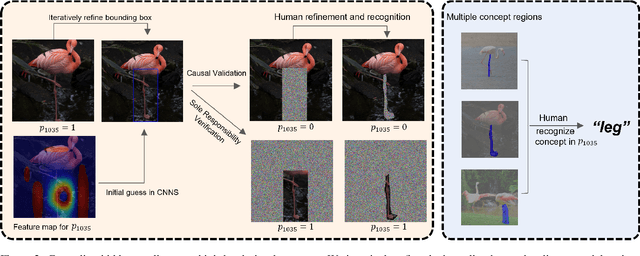

We propose a general framework called VisionLogic to extract interpretable logic rules from deep vision models, with a focus on image classification tasks. Given any deep vision model that uses a fully connected layer as the output head, VisionLogic transforms neurons in the last layer into predicates and grounds them into vision concepts using causal validation. In this way, VisionLogic can provide local explanations for single images and global explanations for specific classes in the form of logic rules. Compared to existing interpretable visualization tools such as saliency maps, VisionLogic addresses several key challenges, including the lack of causal explanations, overconfidence in visualizations, and ambiguity in interpretation. VisionLogic also facilitates the study of visual concepts encoded by predicates, particularly how they behave under perturbation -- an area that remains underexplored in the field of hidden semantics. Apart from providing better visual explanations and insights into the visual concepts learned by the model, we show that VisionLogic retains most of the neural network's discriminative power in an interpretable and transparent manner. We envision it as a bridge between complex model behavior and human-understandable explanations, providing trustworthy and actionable insights for real-world applications.