 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSyncDiT: Cognitive Synchronous Diffusion Transformer for Movie Dubbing
Apr 14, 2026Movie dubbing aims to synthesize speech that preserves the vocal identity of a reference audio while synchronizing with the lip movements in a target video. Existing methods fail to achieve precise lip-sync and lack naturalness due to explicit alignment at the duration level. While implicit alignment solutions have emerged, they remain susceptible to interference from the reference audio, triggering timbre and pronunciation degradation in in-the-wild scenarios. In this paper, we propose a novel flow matching-based movie dubbing framework driven by the Cognitive Synchronous Diffusion Transformer (CoSync-DiT), inspired by the cognitive process of professional actors. This architecture progressively guides the noise-to-speech generative trajectory by executing acoustic style adapting, fine-grained visual calibrating, and time-aware context aligning. Furthermore, we design the Joint Semantic and Alignment Regularization (JSAR) mechanism to simultaneously constrain frame-level temporal consistency on the contextual outputs and semantic consistency on the flow hidden states, ensuring robust alignment. Extensive experiments on both standard benchmarks and challenging in-the-wild dubbing benchmarks demonstrate that our method achieves the state-of-the-art performance across multiple metrics.
STaR: Sensitive Trajectory Regulation for Unlearning in Large Reasoning Models
Jan 14, 2026Large Reasoning Models (LRMs) have advanced automated multi-step reasoning, but their ability to generate complex Chain-of-Thought (CoT) trajectories introduces severe privacy risks, as sensitive information may be deeply embedded throughout the reasoning process. Existing Large Language Models (LLMs) unlearning approaches that typically focus on modifying only final answers are insufficient for LRMs, as they fail to remove sensitive content from intermediate steps, leading to persistent privacy leakage and degraded security. To address these challenges, we propose Sensitive Trajectory Regulation (STaR), a parameter-free, inference-time unlearning framework that achieves robust privacy protection throughout the reasoning process. Specifically, we first identify sensitive content via semantic-aware detection. Then, we inject global safety constraints through secure prompt prefix. Next, we perform trajectory-aware suppression to dynamically block sensitive content across the entire reasoning chain. Finally, we apply token-level adaptive filtering to prevent both exact and paraphrased sensitive tokens during generation. Furthermore, to overcome the inadequacies of existing evaluation protocols, we introduce two metrics: Multi-Decoding Consistency Assessment (MCS), which measures the consistency of unlearning across diverse decoding strategies, and Multi-Granularity Membership Inference Attack (MIA) Evaluation, which quantifies privacy protection at both answer and reasoning-chain levels. Experiments on the R-TOFU benchmark demonstrate that STaR achieves comprehensive and stable unlearning with minimal utility loss, setting a new standard for privacy-preserving reasoning in LRMs.
FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing
May 02, 2025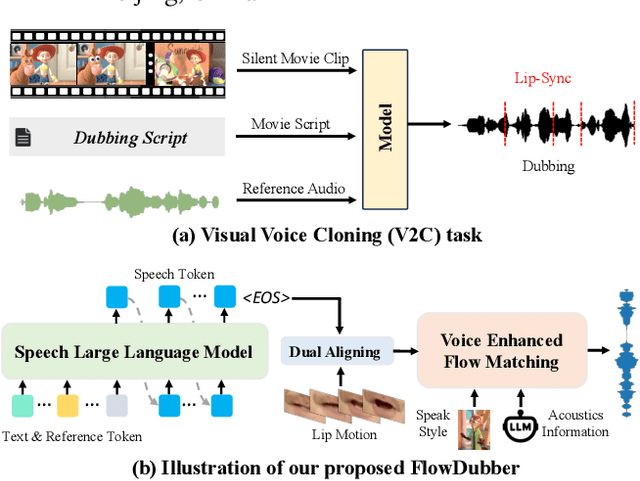
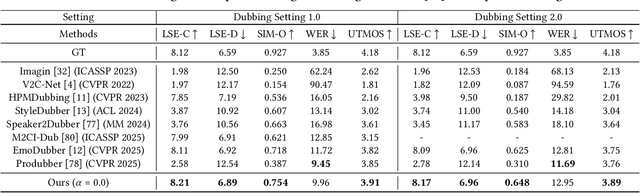
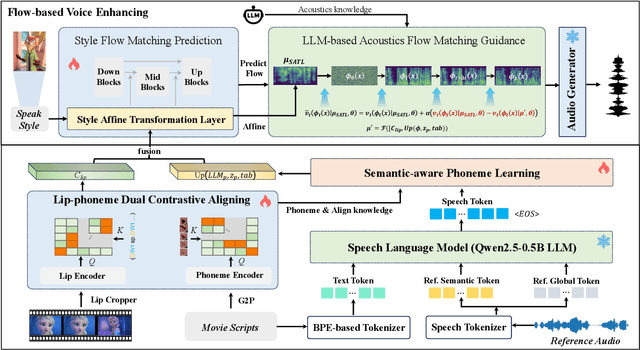
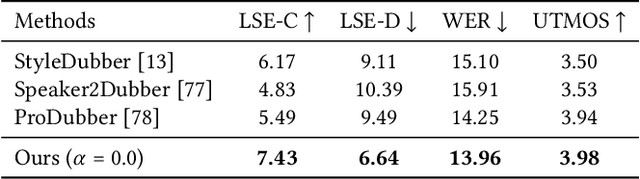
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of a given brief reference audio. Existing methods focus primarily on reducing the word error rate while ignoring the importance of lip-sync and acoustic quality. To address these issues, we propose a large language model (LLM) based flow matching architecture for dubbing, named FlowDubber, which achieves high-quality audio-visual sync and pronunciation by incorporating a large speech language model and dual contrastive aligning while achieving better acoustic quality via the proposed voice-enhanced flow matching than previous works. First, we introduce Qwen2.5 as the backbone of LLM to learn the in-context sequence from movie scripts and reference audio. Then, the proposed semantic-aware learning focuses on capturing LLM semantic knowledge at the phoneme level. Next, dual contrastive aligning (DCA) boosts mutual alignment with lip movement, reducing ambiguities where similar phonemes might be confused. Finally, the proposed Flow-based Voice Enhancing (FVE) improves acoustic quality in two aspects, which introduces an LLM-based acoustics flow matching guidance to strengthen clarity and uses affine style prior to enhance identity when recovering noise into mel-spectrograms via gradient vector field prediction. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks. The demos are available at {\href{https://galaxycong.github.io/LLM-Flow-Dubber/}{\textcolor{red}{https://galaxycong.github.io/LLM-Flow-Dubber/}}}.
Towards Expressive Video Dubbing with Multiscale Multimodal Context Interaction
Dec 25, 2024


Automatic Video Dubbing (AVD) generates speech aligned with lip motion and facial emotion from scripts. Recent research focuses on modeling multimodal context to enhance prosody expressiveness but overlooks two key issues: 1) Multiscale prosody expression attributes in the context influence the current sentence's prosody. 2) Prosody cues in context interact with the current sentence, impacting the final prosody expressiveness. To tackle these challenges, we propose M2CI-Dubber, a Multiscale Multimodal Context Interaction scheme for AVD. This scheme includes two shared M2CI encoders to model the multiscale multimodal context and facilitate its deep interaction with the current sentence. By extracting global and local features for each modality in the context, utilizing attention-based mechanisms for aggregation and interaction, and employing an interaction-based graph attention network for fusion, the proposed approach enhances the prosody expressiveness of synthesized speech for the current sentence. Experiments on the Chem dataset show our model outperforms baselines in dubbing expressiveness. The code and demos are available at \textcolor[rgb]{0.93,0.0,0.47}{https://github.com/AI-S2-Lab/M2CI-Dubber}.
EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing
Dec 12, 2024



Given a piece of text, a video clip, and a reference audio, the movie dubbing task aims to generate speech that aligns with the video while cloning the desired voice. The existing methods have two primary deficiencies: (1) They struggle to simultaneously hold audio-visual sync and achieve clear pronunciation; (2) They lack the capacity to express user-defined emotions. To address these problems, we propose EmoDubber, an emotion-controllable dubbing architecture that allows users to specify emotion type and emotional intensity while satisfying high-quality lip sync and pronunciation. Specifically, we first design Lip-related Prosody Aligning (LPA), which focuses on learning the inherent consistency between lip motion and prosody variation by duration level contrastive learning to incorporate reasonable alignment. Then, we design Pronunciation Enhancing (PE) strategy to fuse the video-level phoneme sequences by efficient conformer to improve speech intelligibility. Next, the speaker identity adapting module aims to decode acoustics prior and inject the speaker style embedding. After that, the proposed Flow-based User Emotion Controlling (FUEC) is used to synthesize waveform by flow matching prediction network conditioned on acoustics prior. In this process, the FUEC determines the gradient direction and guidance scale based on the user's emotion instructions by the positive and negative guidance mechanism, which focuses on amplifying the desired emotion while suppressing others. Extensive experimental results on three benchmark datasets demonstrate favorable performance compared to several state-of-the-art methods.
StyleDubber: Towards Multi-Scale Style Learning for Movie Dubbing
Feb 21, 2024



Given a script, the challenge in Movie Dubbing (Visual Voice Cloning, V2C) is to generate speech that aligns well with the video in both time and emotion, based on the tone of a reference audio track. Existing state-of-the-art V2C models break the phonemes in the script according to the divisions between video frames, which solves the temporal alignment problem but leads to incomplete phoneme pronunciation and poor identity stability. To address this problem, we propose StyleDubber, which switches dubbing learning from the frame level to phoneme level. It contains three main components: (1) A multimodal style adaptor operating at the phoneme level to learn pronunciation style from the reference audio, and generate intermediate representations informed by the facial emotion presented in the video; (2) An utterance-level style learning module, which guides both the mel-spectrogram decoding and the refining processes from the intermediate embeddings to improve the overall style expression; And (3) a phoneme-guided lip aligner to maintain lip sync. Extensive experiments on two of the primary benchmarks, V2C and Grid, demonstrate the favorable performance of the proposed method as compared to the current state-of-the-art. The source code and trained models will be released to the public.
Learning to Dub Movies via Hierarchical Prosody Models
Dec 08, 2022Given a piece of text, a video clip and a reference audio, the movie dubbing (also known as visual voice clone V2C) task aims to generate speeches that match the speaker's emotion presented in the video using the desired speaker voice as reference. V2C is more challenging than conventional text-to-speech tasks as it additionally requires the generated speech to exactly match the varying emotions and speaking speed presented in the video. Unlike previous works, we propose a novel movie dubbing architecture to tackle these problems via hierarchical prosody modelling, which bridges the visual information to corresponding speech prosody from three aspects: lip, face, and scene. Specifically, we align lip movement to the speech duration, and convey facial expression to speech energy and pitch via attention mechanism based on valence and arousal representations inspired by recent psychology findings. Moreover, we design an emotion booster to capture the atmosphere from global video scenes. All these embeddings together are used to generate mel-spectrogram and then convert to speech waves via existing vocoder. Extensive experimental results on the Chem and V2C benchmark datasets demonstrate the favorable performance of the proposed method. The source code and trained models will be released to the public.