 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Feb 19, 2025Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba'' model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba's potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
OPa-Ma: Text Guided Mamba for 360-degree Image Out-painting
Jul 15, 2024In this paper, we tackle the recently popular topic of generating 360-degree images given the conventional narrow field of view (NFoV) images that could be taken from a single camera or cellphone. This task aims to predict the reasonable and consistent surroundings from the NFoV images. Existing methods for feature extraction and fusion, often built with transformer-based architectures, incur substantial memory usage and computational expense. They also have limitations in maintaining visual continuity across the entire 360-degree images, which could cause inconsistent texture and style generation. To solve the aforementioned issues, we propose a novel text-guided out-painting framework equipped with a State-Space Model called Mamba to utilize its long-sequence modelling and spatial continuity. Furthermore, incorporating textual information is an effective strategy for guiding image generation, enriching the process with detailed context and increasing diversity. Efficiently extracting textual features and integrating them with image attributes presents a significant challenge for 360-degree image out-painting. To address this, we develop two modules, Visual-textual Consistency Refiner (VCR) and Global-local Mamba Adapter (GMA). VCR enhances contextual richness by fusing the modified text features with the image features, while GMA provides adaptive state-selective conditions by capturing the information flow from global to local representations. Our proposed method achieves state-of-the-art performance with extensive experiments on two broadly used 360-degree image datasets, including indoor and outdoor settings.
Probabilistically Safe Robot Planning with Confidence-Based Human Predictions
May 31, 2018
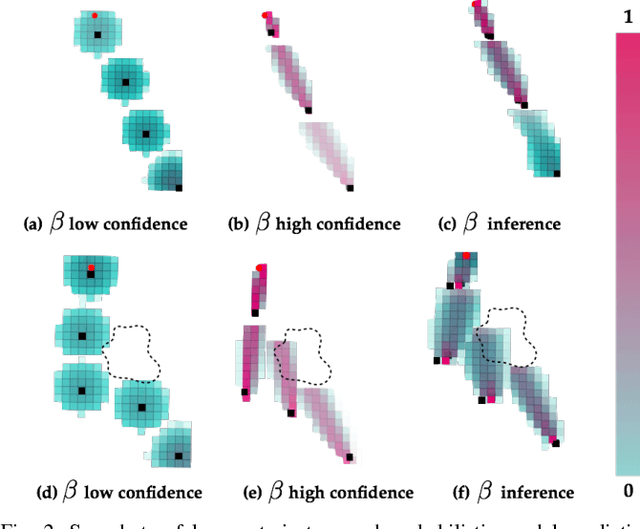
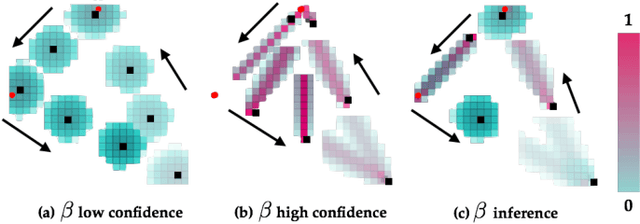
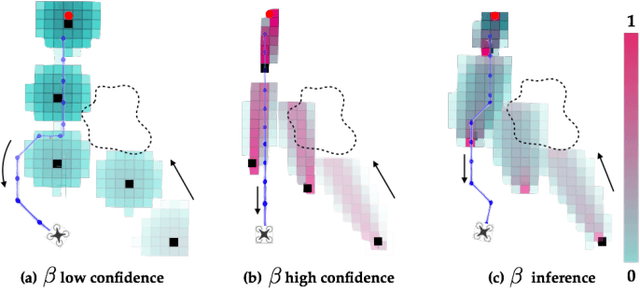
In order to safely operate around humans, robots can employ predictive models of human motion. Unfortunately, these models cannot capture the full complexity of human behavior and necessarily introduce simplifying assumptions. As a result, predictions may degrade whenever the observed human behavior departs from the assumed structure, which can have negative implications for safety. In this paper, we observe that how "rational" human actions appear under a particular model can be viewed as an indicator of that model's ability to describe the human's current motion. By reasoning about this model confidence in a real-time Bayesian framework, we show that the robot can very quickly modulate its predictions to become more uncertain when the model performs poorly. Building on recent work in provably-safe trajectory planning, we leverage these confidence-aware human motion predictions to generate assured autonomous robot motion. Our new analysis combines worst-case tracking error guarantees for the physical robot with probabilistic time-varying human predictions, yielding a quantitative, probabilistic safety certificate. We demonstrate our approach with a quadcopter navigating around a human.