 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAST: Gradient-aligned Sparse Tuning of Large Language Models with Data-layer Selection
Mar 10, 2026Parameter-Efficient Fine-Tuning (PEFT) has become a key strategy for adapting large language models, with recent advances in sparse tuning reducing overhead by selectively updating key parameters or subsets of data. Existing approaches generally focus on two distinct paradigms: layer-selective methods aiming to fine-tune critical layers to minimize computational load, and data-selective methods aiming to select effective training subsets to boost training. However, current methods typically overlook the fact that different data points contribute varying degrees to distinct model layers, and they often discard potentially valuable information from data perceived as of low quality. To address these limitations, we propose Gradient-aligned Sparse Tuning (GAST), an innovative method that simultaneously performs selective fine-tuning at both data and layer dimensions as integral components of a unified optimization strategy. GAST specifically targets redundancy in information by employing a layer-sparse strategy that adaptively selects the most impactful data points for each layer, providing a more comprehensive and sophisticated solution than approaches restricted to a single dimension. Experiments demonstrate that GAST consistently outperforms baseline methods, establishing a promising direction for future research in PEFT strategies.
OPa-Ma: Text Guided Mamba for 360-degree Image Out-painting
Jul 15, 2024In this paper, we tackle the recently popular topic of generating 360-degree images given the conventional narrow field of view (NFoV) images that could be taken from a single camera or cellphone. This task aims to predict the reasonable and consistent surroundings from the NFoV images. Existing methods for feature extraction and fusion, often built with transformer-based architectures, incur substantial memory usage and computational expense. They also have limitations in maintaining visual continuity across the entire 360-degree images, which could cause inconsistent texture and style generation. To solve the aforementioned issues, we propose a novel text-guided out-painting framework equipped with a State-Space Model called Mamba to utilize its long-sequence modelling and spatial continuity. Furthermore, incorporating textual information is an effective strategy for guiding image generation, enriching the process with detailed context and increasing diversity. Efficiently extracting textual features and integrating them with image attributes presents a significant challenge for 360-degree image out-painting. To address this, we develop two modules, Visual-textual Consistency Refiner (VCR) and Global-local Mamba Adapter (GMA). VCR enhances contextual richness by fusing the modified text features with the image features, while GMA provides adaptive state-selective conditions by capturing the information flow from global to local representations. Our proposed method achieves state-of-the-art performance with extensive experiments on two broadly used 360-degree image datasets, including indoor and outdoor settings.
EgPDE-Net: Building Continuous Neural Networks for Time Series Prediction with Exogenous Variables
Aug 03, 2022



While exogenous variables have a major impact on performance improvement in time series analysis, inter-series correlation and time dependence among them are rarely considered in the present continuous methods. The dynamical systems of multivariate time series could be modelled with complex unknown partial differential equations (PDEs) which play a prominent role in many disciplines of science and engineering. In this paper, we propose a continuous-time model for arbitrary-step prediction to learn an unknown PDE system in multivariate time series whose governing equations are parameterised by self-attention and gated recurrent neural networks. The proposed model, \underline{E}xogenous-\underline{g}uided \underline{P}artial \underline{D}ifferential \underline{E}quation Network (EgPDE-Net), takes account of the relationships among the exogenous variables and their effects on the target series. Importantly, the model can be reduced into a regularised ordinary differential equation (ODE) problem with special designed regularisation guidance, which makes the PDE problem tractable to obtain numerical solutions and feasible to predict multiple future values of the target series at arbitrary time points. Extensive experiments demonstrate that our proposed model could achieve competitive accuracy over strong baselines: on average, it outperforms the best baseline by reducing $9.85\%$ on RMSE and $13.98\%$ on MAE for arbitrary-step prediction.
Outpainting by Queries
Jul 12, 2022



Image outpainting, which is well studied with Convolution Neural Network (CNN) based framework, has recently drawn more attention in computer vision. However, CNNs rely on inherent inductive biases to achieve effective sample learning, which may degrade the performance ceiling. In this paper, motivated by the flexible self-attention mechanism with minimal inductive biases in transformer architecture, we reframe the generalised image outpainting problem as a patch-wise sequence-to-sequence autoregression problem, enabling query-based image outpainting. Specifically, we propose a novel hybrid vision-transformer-based encoder-decoder framework, named \textbf{Query} \textbf{O}utpainting \textbf{TR}ansformer (\textbf{QueryOTR}), for extrapolating visual context all-side around a given image. Patch-wise mode's global modeling capacity allows us to extrapolate images from the attention mechanism's query standpoint. A novel Query Expansion Module (QEM) is designed to integrate information from the predicted queries based on the encoder's output, hence accelerating the convergence of the pure transformer even with a relatively small dataset. To further enhance connectivity between each patch, the proposed Patch Smoothing Module (PSM) re-allocates and averages the overlapped regions, thus providing seamless predicted images. We experimentally show that QueryOTR could generate visually appealing results smoothly and realistically against the state-of-the-art image outpainting approaches.
Generalised Image Outpainting with U-Transformer
Jan 27, 2022


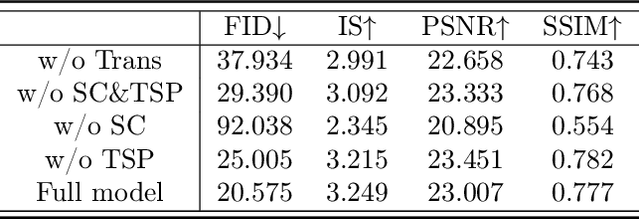
While most present image outpainting conducts horizontal extrapolation, we study the generalised image outpainting problem that extrapolates visual context all-side around a given image. To this end, we develop a novel transformer-based generative adversarial network called U-Transformer able to extend image borders with plausible structure and details even for complicated scenery images. Specifically, we design a generator as an encoder-to-decoder structure embedded with the popular Swin Transformer blocks. As such, our novel framework can better cope with image long-range dependencies which are crucially important for generalised image outpainting. We propose additionally a U-shaped structure and multi-view Temporal Spatial Predictor network to reinforce image self-reconstruction as well as unknown-part prediction smoothly and realistically. We experimentally demonstrate that our proposed method could produce visually appealing results for generalized image outpainting against the state-of-the-art image outpainting approaches.
Explainable Tensorized Neural Ordinary Differential Equations forArbitrary-step Time Series Prediction
Nov 26, 2020
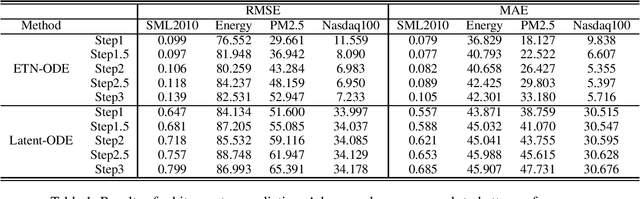
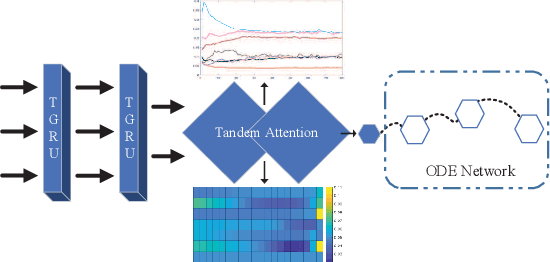
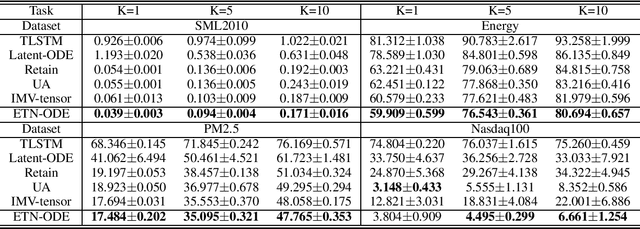
We propose a continuous neural network architecture, termed Explainable Tensorized Neural Ordinary Differential Equations (ETN-ODE), for multi-step time series prediction at arbitrary time points. Unlike the existing approaches, which mainly handle univariate time series for multi-step prediction or multivariate time series for single-step prediction, ETN-ODE could model multivariate time series for arbitrary-step prediction. In addition, it enjoys a tandem attention, w.r.t. temporal attention and variable attention, being able to provide explainable insights into the data. Specifically, ETN-ODE combines an explainable Tensorized Gated Recurrent Unit (Tensorized GRU or TGRU) with Ordinary Differential Equations (ODE). The derivative of the latent states is parameterized with a neural network. This continuous-time ODE network enables a multi-step prediction at arbitrary time points. We quantitatively and qualitatively demonstrate the effectiveness and the interpretability of ETN-ODE on five different multi-step prediction tasks and one arbitrary-step prediction task. Extensive experiments show that ETN-ODE can lead to accurate predictions at arbitrary time points while attaining best performance against the baseline methods in standard multi-step time series prediction.