 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
Consistency Diffusion Models for Single-Image 3D Reconstruction with Priors
Jan 31, 2025This paper delves into the study of 3D point cloud reconstruction from a single image. Our objective is to develop the Consistency Diffusion Model, exploring synergistic 2D and 3D priors in the Bayesian framework to ensure superior consistency in the reconstruction process, a challenging yet critical requirement in this field. Specifically, we introduce a pioneering training framework under diffusion models that brings two key innovations. First, we convert 3D structural priors derived from the initial 3D point cloud as a bound term to increase evidence in the variational Bayesian framework, leveraging these robust intrinsic priors to tightly govern the diffusion training process and bolster consistency in reconstruction. Second, we extract and incorporate 2D priors from the single input image, projecting them onto the 3D point cloud to enrich the guidance for diffusion training. Our framework not only sidesteps potential model learning shifts that may arise from directly imposing additional constraints during training but also precisely transposes the 2D priors into the 3D domain. Extensive experimental evaluations reveal that our approach sets new benchmarks in both synthetic and real-world datasets. The code is included with the submission.
Towards Cross-device and Training-free Robotic Grasping in 3D Open World
Nov 27, 2024Robotic grasping in the open world is a critical component of manufacturing and automation processes. While numerous existing approaches depend on 2D segmentation output to facilitate the grasping procedure, accurately determining depth from 2D imagery remains a challenge, often leading to limited performance in complex stacking scenarios. In contrast, techniques utilizing 3D point cloud data inherently capture depth information, thus enabling adeptly navigating and manipulating a diverse range of complex stacking scenes. However, such efforts are considerably hindered by the variance in data capture devices and the unstructured nature of the data, which limits their generalizability. Consequently, much research is narrowly concentrated on managing designated objects within specific settings, which confines their real-world applicability. This paper presents a novel pipeline capable of executing object grasping tasks in open-world scenarios even on previously unseen objects without the necessity for training. Additionally, our pipeline supports the flexible use of different 3D point cloud segmentation models across a variety of scenes. Leveraging the segmentation results, we propose to engage a training-free binary clustering algorithm that not only improves segmentation precision but also possesses the capability to cluster and localize unseen objects for executing grasping operations. In our experiments, we investigate a range of open-world scenarios, and the outcomes underscore the remarkable robustness and generalizability of our pipeline, consistent across various environments, robots, cameras, and objects. The code will be made available upon acceptance of the paper.
Diff-OP3D: Bridging 2D Diffusion for Open Pose 3D Zero-Shot Classification
Dec 12, 2023With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, the methods via transferring Contrastive Language-Image Pre-training (CLIP) to 3D vision have made great progress in the 3D zero-shot classification task. However, these methods primarily focus on aligned pose 3D objects (ap-3os), overlooking the recognition of 3D objects with open poses (op-3os) typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more challenging benchmark for 3D open-pose zero-shot classification. Echoing our benchmark, we design a concise angle-refinement mechanism that automatically optimizes one ideal pose as well as classifies these op-3os. Furthermore, we make a first attempt to bridge 2D pre-trained diffusion model as a classifer to 3D zero-shot classification without any additional training. Such 2D diffusion to 3D objects proves vital in improving zero-shot classification for both ap-3os and op-3os. Our model notably improves by 3.5% and 15.8% on ModelNet10$^{\ddag}$ and McGill$^{\ddag}$ open pose benchmarks, respectively, and surpasses the current state-of-the-art by 6.8% on the aligned pose ModelNet10, affirming diffusion's efficacy in 3D zero-shot tasks.
Towards Simple and Accurate Human Pose Estimation with Stair Network
Feb 18, 2022

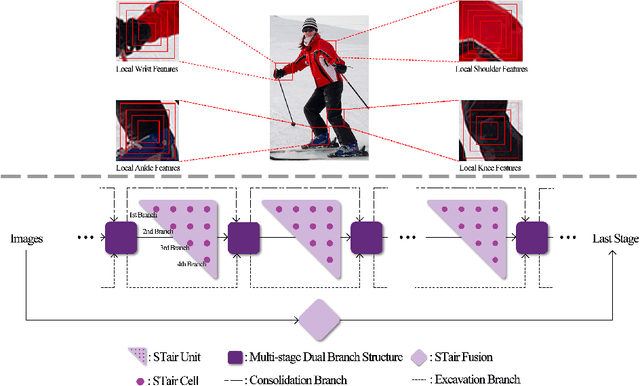

In this paper, we focus on tackling the precise keypoint coordinates regression task. Most existing approaches adopt complicated networks with a large number of parameters, leading to a heavy model with poor cost-effectiveness in practice. To overcome this limitation, we develop a small yet discrimicative model called STair Network, which can be simply stacked towards an accurate multi-stage pose estimation system. Specifically, to reduce computational cost, STair Network is composed of novel basic feature extraction blocks which focus on promoting feature diversity and obtaining rich local representations with fewer parameters, enabling a satisfactory balance on efficiency and performance. To further improve the performance, we introduce two mechanisms with negligible computational cost, focusing on feature fusion and replenish. We demonstrate the effectiveness of the STair Network on two standard datasets, e.g., 1-stage STair Network achieves a higher accuracy than HRNet by 5.5% on COCO test dataset with 80\% fewer parameters and 68% fewer GFLOPs.