 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom 2D Images to 3D Model:Weakly Supervised Multi-View Face Reconstruction with Deep Fusion
Paper and Code
Apr 08, 2022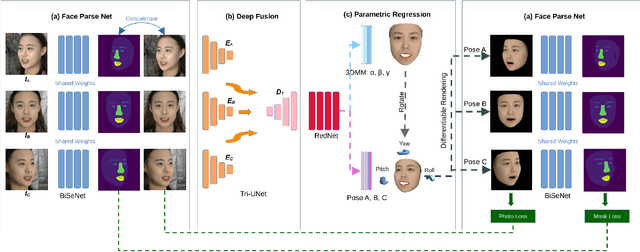

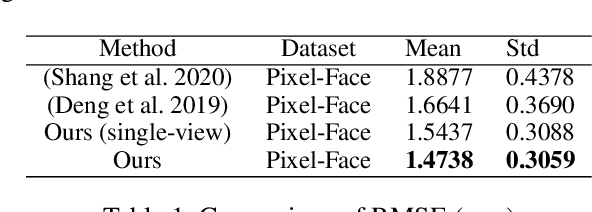
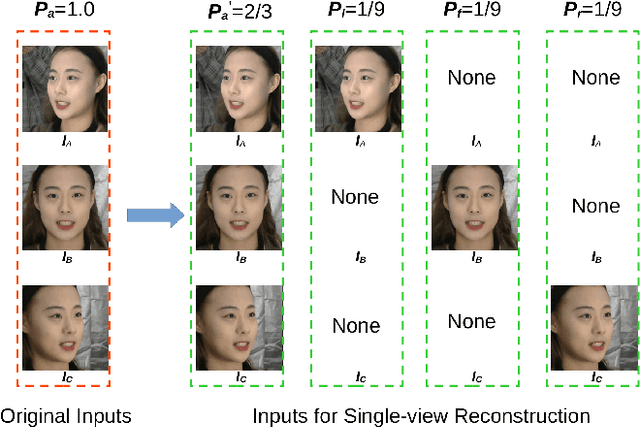
We consider the problem of Multi-view 3D Face Reconstruction (MVR) with weakly supervised learning that leverages a limited number of 2D face images (e.g. 3) to generate a high-quality 3D face model with very light annotation. Despite their encouraging performance, present MVR methods simply concatenate multi-view image features and pay less attention to critical areas (e.g. eye, brow, nose and mouth). To this end, we propose a novel model called Deep Fusion MVR (DF-MVR) and design a multi-view encoding to a single decoding framework with skip connections, able to extract, integrate, and compensate deep features with attention from multi-view images. In addition, we develop a multi-view face parse network to learn, identify, and emphasize the critical common face area. Finally, though our model is trained with a few 2D images, it can reconstruct an accurate 3D model even if one single 2D image is input. We conduct extensive experiments to evaluate various multi-view 3D face reconstruction methods. Our proposed model attains superior performance, leading to 11.4% RMSE improvement over the existing best weakly supervised MVRs. Source codes are available in the supplementary materials.