 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILOT: Policy-Informed Learned Optimization for Adaptive Deep Network Training
May 23, 2026Despite the central role of optimization in deep learning, most optimizers rely on update structures whose functional form is fixed before training begins. This static design can limit their ability to respond to changing gradient behavior across the loss landscape, where training may shift between stable, noisy, and inconsistent regimes. This study proposes PILOT (Policy-Informed Learned OpTimizer), an online optimizer that adapts its update behavior during training. Rather than using a fixed balance between momentum, normalization, and sign-based updates, PILOT uses gradient-direction agreement as a signal of local training stability. Conditioning the update rule on this agreement signal allows the optimizer to adjust its behavior when gradients become stable, noisy, or inconsistent. Experiments on FashionMNIST and CIFAR-10 show that PILOT consistently achieves the highest accuracy among the evaluated optimizers across convolutional settings. On the CNN architecture, PILOT reaches 94.13% on FashionMNIST and 81.94% on CIFAR-10. On ResNet-18, it further improves performance, reaching 95.71% on FashionMNIST and 93.42% on CIFAR-10. These results suggest that learning how to adapt the update structure during training can improve performance across both compact and deeper convolutional models while preserving a simple first-order optimization framework. The implementation of PILOT is publicly available at https://github.com/SattamAltwaim/PILOT.git
Epistemic Generative Adversarial Networks
Mar 18, 2026Generative models, particularly Generative Adversarial Networks (GANs), often suffer from a lack of output diversity, frequently generating similar samples rather than a wide range of variations. This paper introduces a novel generalization of the GAN loss function based on Dempster-Shafer theory of evidence, applied to both the generator and discriminator. Additionally, we propose an architectural enhancement to the generator that enables it to predict a mass function for each image pixel. This modification allows the model to quantify uncertainty in its outputs and leverage this uncertainty to produce more diverse and representative generations. Experimental evidence shows that our approach not only improves generation variability but also provides a principled framework for modeling and interpreting uncertainty in generative processes.
Epistemic Wrapping for Uncertainty Quantification
May 04, 2025Uncertainty estimation is pivotal in machine learning, especially for classification tasks, as it improves the robustness and reliability of models. We introduce a novel `Epistemic Wrapping' methodology aimed at improving uncertainty estimation in classification. Our approach uses Bayesian Neural Networks (BNNs) as a baseline and transforms their outputs into belief function posteriors, effectively capturing epistemic uncertainty and offering an efficient and general methodology for uncertainty quantification. Comprehensive experiments employing a Bayesian Neural Network (BNN) baseline and an Interval Neural Network for inference on the MNIST, Fashion-MNIST, CIFAR-10 and CIFAR-100 datasets demonstrate that our Epistemic Wrapper significantly enhances generalisation and uncertainty quantification.
Random-Set Large Language Models
Apr 25, 2025Large Language Models (LLMs) are known to produce very high-quality tests and responses to our queries. But how much can we trust this generated text? In this paper, we study the problem of uncertainty quantification in LLMs. We propose a novel Random-Set Large Language Model (RSLLM) approach which predicts finite random sets (belief functions) over the token space, rather than probability vectors as in classical LLMs. In order to allow so efficiently, we also present a methodology based on hierarchical clustering to extract and use a budget of "focal" subsets of tokens upon which the belief prediction is defined, rather than using all possible collections of tokens, making the method scalable yet effective. RS-LLMs encode the epistemic uncertainty induced in their generation process by the size and diversity of its training set via the size of the credal sets associated with the predicted belief functions. The proposed approach is evaluated on CoQA and OBQA datasets using Llama2-7b, Mistral-7b and Phi-2 models and is shown to outperform the standard model in both datasets in terms of correctness of answer while also showing potential in estimating the second level uncertainty in its predictions and providing the capability to detect when its hallucinating.
A Unified Evaluation Framework for Epistemic Predictions
Jan 28, 2025Predictions of uncertainty-aware models are diverse, ranging from single point estimates (often averaged over prediction samples) to predictive distributions, to set-valued or credal-set representations. We propose a novel unified evaluation framework for uncertainty-aware classifiers, applicable to a wide range of model classes, which allows users to tailor the trade-off between accuracy and precision of predictions via a suitably designed performance metric. This makes possible the selection of the most suitable model for a particular real-world application as a function of the desired trade-off. Our experiments, concerning Bayesian, ensemble, evidential, deterministic, credal and belief function classifiers on the CIFAR-10, MNIST and CIFAR-100 datasets, show that the metric behaves as desired.
Random-Set Convolutional Neural Network (RS-CNN) for Epistemic Deep Learning
Jul 11, 2023



Machine learning is increasingly deployed in safety-critical domains where robustness against adversarial attacks is crucial and erroneous predictions could lead to potentially catastrophic consequences. This highlights the need for learning systems to be equipped with the means to determine a model's confidence in its prediction and the epistemic uncertainty associated with it, 'to know when a model does not know'. In this paper, we propose a novel Random-Set Convolutional Neural Network (RS-CNN) for classification which predicts belief functions rather than probability vectors over the set of classes, using the mathematics of random sets, i.e., distributions over the power set of the sample space. Based on the epistemic deep learning approach, random-set models are capable of representing the 'epistemic' uncertainty induced in machine learning by limited training sets. We estimate epistemic uncertainty by approximating the size of credal sets associated with the predicted belief functions, and experimentally demonstrate how our approach outperforms competing uncertainty-aware approaches in a classical evaluation setting. The performance of RS-CNN is best demonstrated on OOD samples where it manages to capture the true prediction while standard CNNs fail.
Class-Agnostic Segmentation Loss and Its Application to Salient Object Detection and Segmentation
Jul 16, 2021
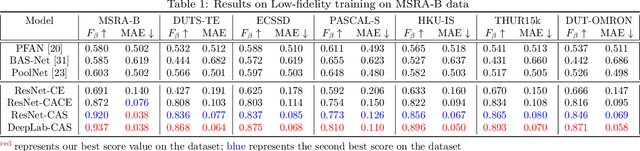

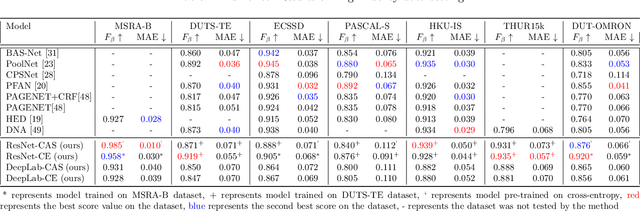
In this paper we present a novel loss function, called class-agnostic segmentation (CAS) loss. With CAS loss the class descriptors are learned during training of the network. We don't require to define the label of a class a-priori, rather the CAS loss clusters regions with similar appearance together in a weakly-supervised manner. Furthermore, we show that the CAS loss function is sparse, bounded, and robust to class-imbalance. We first apply our CAS loss function with fully-convolutional ResNet101 and DeepLab-v3 architectures to the binary segmentation problem of salient object detection. We investigate the performance against the state-of-the-art methods in two settings of low and high-fidelity training data on seven salient object detection datasets. For low-fidelity training data (incorrect class label) class-agnostic segmentation loss outperforms the state-of-the-art methods on salient object detection datasets by staggering margins of around 50%. For high-fidelity training data (correct class labels) class-agnostic segmentation models perform as good as the state-of-the-art approaches while beating the state-of-the-art methods on most datasets. In order to show the utility of the loss function across different domains we then also test on general segmentation dataset, where class-agnostic segmentation loss outperforms competing losses by huge margins.