 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Autonomous Vehicles: Predicting the Road Ahead
Oct 26, 2025Autonomous Vehicle (AV) perception systems have advanced rapidly in recent years, providing vehicles with the ability to accurately interpret their environment. Perception systems remain susceptible to errors caused by overly-confident predictions in the case of rare events or out-of-sample data. This study equips an autonomous vehicle with the ability to 'know when it is uncertain', using an uncertainty-aware image classifier as part of the AV software stack. Specifically, the study exploits the ability of Random-Set Neural Networks (RS-NNs) to explicitly quantify prediction uncertainty. Unlike traditional CNNs or Bayesian methods, RS-NNs predict belief functions over sets of classes, allowing the system to identify and signal uncertainty clearly in novel or ambiguous scenarios. The system is tested in a real-world autonomous racing vehicle software stack, with the RS-NN classifying the layout of the road ahead and providing the associated uncertainty of the prediction. Performance of the RS-NN under a range of road conditions is compared against traditional CNN and Bayesian neural networks, with the RS-NN achieving significantly higher accuracy and superior uncertainty calibration. This integration of RS-NNs into Robot Operating System (ROS)-based vehicle control pipeline demonstrates that predictive uncertainty can dynamically modulate vehicle speed, maintaining high-speed performance under confident predictions while proactively improving safety through speed reductions in uncertain scenarios. These results demonstrate the potential of uncertainty-aware neural networks - in particular RS-NNs - as a practical solution for safer and more robust autonomous driving.
Epistemic Wrapping for Uncertainty Quantification
May 04, 2025Uncertainty estimation is pivotal in machine learning, especially for classification tasks, as it improves the robustness and reliability of models. We introduce a novel `Epistemic Wrapping' methodology aimed at improving uncertainty estimation in classification. Our approach uses Bayesian Neural Networks (BNNs) as a baseline and transforms their outputs into belief function posteriors, effectively capturing epistemic uncertainty and offering an efficient and general methodology for uncertainty quantification. Comprehensive experiments employing a Bayesian Neural Network (BNN) baseline and an Interval Neural Network for inference on the MNIST, Fashion-MNIST, CIFAR-10 and CIFAR-100 datasets demonstrate that our Epistemic Wrapper significantly enhances generalisation and uncertainty quantification.
Credal Learning Theory
Feb 01, 2024
Statistical learning theory is the foundation of machine learning, providing theoretical bounds for the risk of models learnt from a (single) training set, assumed to issue from an unknown probability distribution. In actual deployment, however, the data distribution may (and often does) vary, causing domain adaptation/generalization issues. In this paper we lay the foundations for a `credal' theory of learning, using convex sets of probabilities (credal sets) to model the variability in the data-generating distribution. Such credal sets, we argue, may be inferred from a finite sample of training sets. Bounds are derived for the case of finite hypotheses spaces (both assuming realizability or not) as well as infinite model spaces, which directly generalize classical results.
Self-Distilled Vision Transformer for Domain Generalization
Aug 12, 2022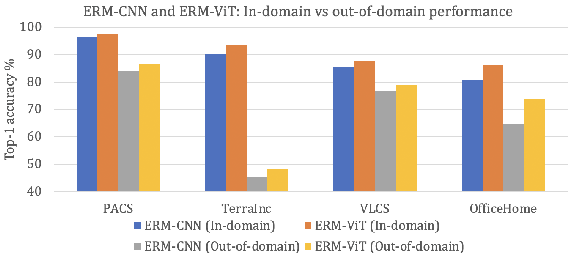
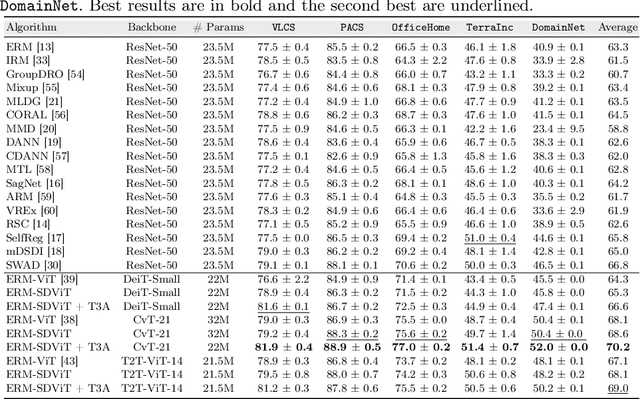

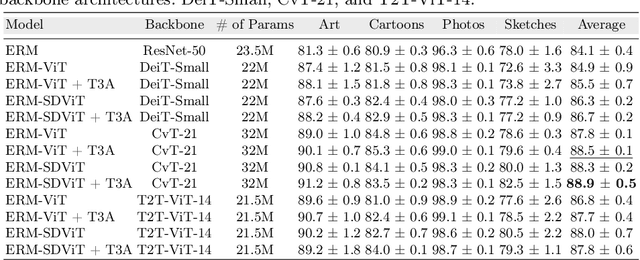
In recent past, several domain generalization (DG) methods have been proposed, showing encouraging performance, however, almost all of them build on convolutional neural networks (CNNs). There is little to no progress on studying the DG performance of vision transformers (ViTs), which are challenging the supremacy of CNNs on standard benchmarks, often built on i.i.d assumption. This renders the real-world deployment of ViTs doubtful. In this paper, we attempt to explore ViTs towards addressing the DG problem. Similar to CNNs, ViTs also struggle in out-of-distribution scenarios and the main culprit is overfitting to source domains. Inspired by the modular architecture of ViTs, we propose a simple DG approach for ViTs, coined as self-distillation for ViTs. It reduces the overfitting to source domains by easing the learning of input-output mapping problem through curating non-zero entropy supervisory signals for intermediate transformer blocks. Further, it does not introduce any new parameters and can be seamlessly plugged into the modular composition of different ViTs. We empirically demonstrate notable performance gains with different DG baselines and various ViT backbones in five challenging datasets. Moreover, we report favorable performance against recent state-of-the-art DG methods. Our code along with pre-trained models are publicly available at: https://github.com/maryam089/SDViT
Illumination Invariant Foreground Object Segmentation using ForeGANs
Apr 05, 2019
The foreground segmentation algorithms suffer performance degradation in the presence of various challenges such as dynamic backgrounds, and various illumination conditions. To handle these challenges, we present a foreground segmentation method, based on generative adversarial network (GAN). We aim to segment foreground objects in the presence of two aforementioned major challenges in background scenes in real environments. To address this problem, our presented GAN model is trained on background image samples with dynamic changes, after that for testing the GAN model has to generate the same background sample as test sample with similar conditions via back-propagation technique. The generated background sample is then subtracted from the given test sample to segment foreground objects. The comparison of our proposed method with five state-of-the-art methods highlights the strength of our algorithm for foreground segmentation in the presence of challenging dynamic background scenario.
Deep Neural Network Concepts for Background Subtraction: A Systematic Review and Comparative Evaluation
Nov 13, 2018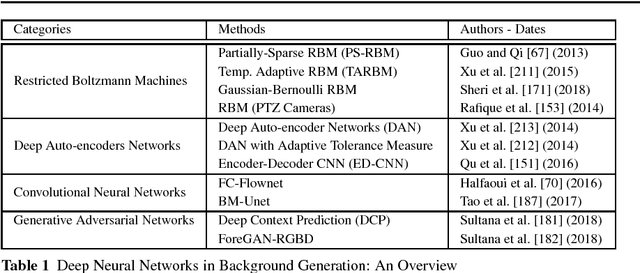

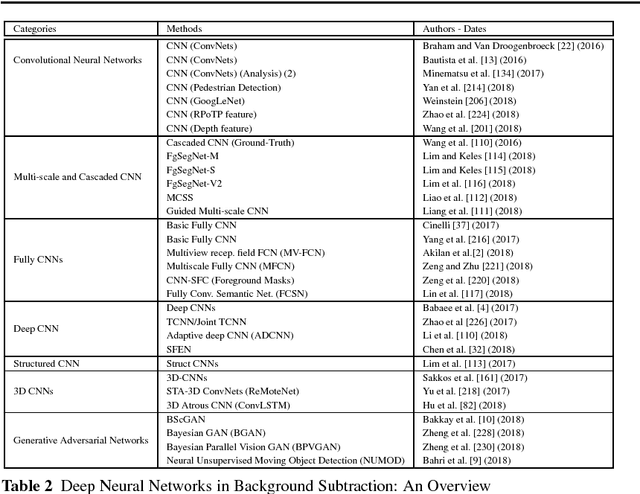

Conventional neural networks show a powerful framework for background subtraction in video acquired by static cameras. Indeed, the well-known SOBS method and its variants based on neural networks were the leader methods on the largescale CDnet 2012 dataset during a long time. Recently, convolutional neural networks which belong to deep learning methods were employed with success for background initialization, foreground detection and deep learned features. Currently, the top current background subtraction methods in CDnet 2014 are based on deep neural networks with a large gap of performance in comparison on the conventional unsupervised approaches based on multi-features or multi-cues strategies. Furthermore, a huge amount of papers was published since 2016 when Braham and Van Droogenbroeck published their first work on CNN applied to background subtraction providing a regular gain of performance. In this context, we provide the first review of deep neural network concepts in background subtraction for novices and experts in order to analyze this success and to provide further directions. For this, we first surveyed the methods used background initialization, background subtraction and deep learned features. Then, we discuss the adequacy of deep neural networks for background subtraction. Finally, experimental results are presented on the CDnet 2014 dataset.
Unsupervised RGBD Video Object Segmentation Using GANs
Nov 05, 2018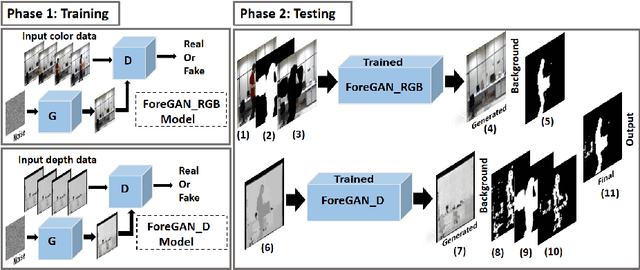


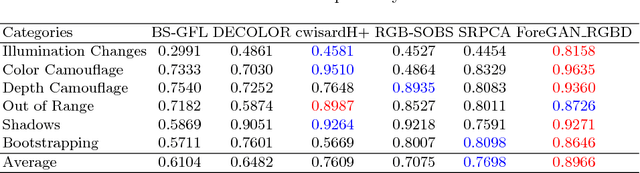
Video object segmentation is a fundamental step in many advanced vision applications. Most existing algorithms are based on handcrafted features such as HOG, super-pixel segmentation or texture-based techniques, while recently deep features have been found to be more efficient. Existing algorithms observe performance degradation in the presence of challenges such as illumination variations, shadows, and color camouflage. To handle these challenges we propose a fusion based moving object segmentation algorithm which exploits color as well as depth information using GAN to achieve more accuracy. Our goal is to segment moving objects in the presence of challenging background scenes, in real environments. To address this problem, GAN is trained in an unsupervised manner on color and depth information independently with challenging video sequences. During testing, the trained GAN generates backgrounds similar to that in the test sample. The generated background samples are then compared with the test sample to segment moving objects. The final result is computed by fusion of object boundaries in both modalities, RGB and the depth. The comparison of our proposed algorithm with five state-of-the-art methods on publicly available dataset has shown the strength of our algorithm for moving object segmentation in videos in the presence of challenging real scenarios.
Unsupervised Deep Context Prediction for Background Foreground Separation
May 21, 2018

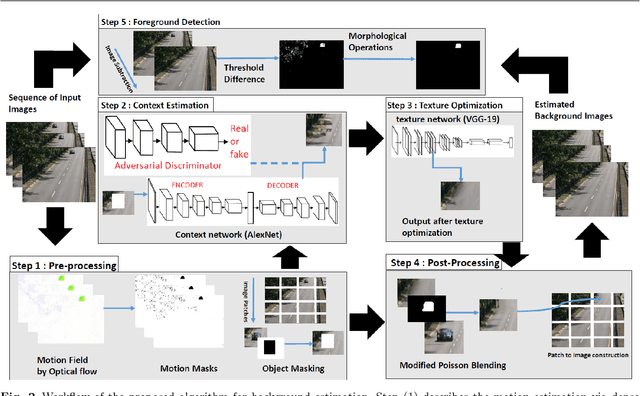

In many advanced video based applications background modeling is a pre-processing step to eliminate redundant data, for instance in tracking or video surveillance applications. Over the past years background subtraction is usually based on low level or hand-crafted features such as raw color components, gradients, or local binary patterns. The background subtraction algorithms performance suffer in the presence of various challenges such as dynamic backgrounds, photometric variations, camera jitters, and shadows. To handle these challenges for the purpose of accurate background modeling we propose a unified framework based on the algorithm of image inpainting. It is an unsupervised visual feature learning hybrid Generative Adversarial algorithm based on context prediction. We have also presented the solution of random region inpainting by the fusion of center region inpaiting and random region inpainting with the help of poisson blending technique. Furthermore we also evaluated foreground object detection with the fusion of our proposed method and morphological operations. The comparison of our proposed method with 12 state-of-the-art methods shows its stability in the application of background estimation and foreground detection.
* 17 pages