 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Vision Transformer for Domain Generalization
Paper and Code
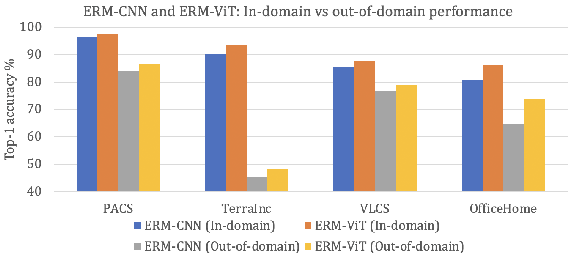
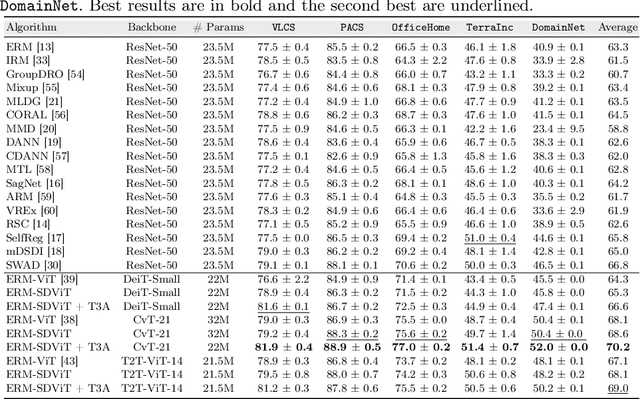

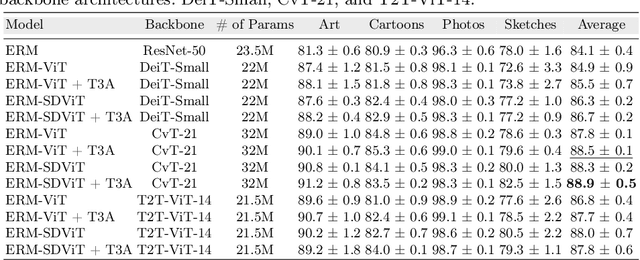
In recent past, several domain generalization (DG) methods have been proposed, showing encouraging performance, however, almost all of them build on convolutional neural networks (CNNs). There is little to no progress on studying the DG performance of vision transformers (ViTs), which are challenging the supremacy of CNNs on standard benchmarks, often built on i.i.d assumption. This renders the real-world deployment of ViTs doubtful. In this paper, we attempt to explore ViTs towards addressing the DG problem. Similar to CNNs, ViTs also struggle in out-of-distribution scenarios and the main culprit is overfitting to source domains. Inspired by the modular architecture of ViTs, we propose a simple DG approach for ViTs, coined as self-distillation for ViTs. It reduces the overfitting to source domains by easing the learning of input-output mapping problem through curating non-zero entropy supervisory signals for intermediate transformer blocks. Further, it does not introduce any new parameters and can be seamlessly plugged into the modular composition of different ViTs. We empirically demonstrate notable performance gains with different DG baselines and various ViT backbones in five challenging datasets. Moreover, we report favorable performance against recent state-of-the-art DG methods. Our code along with pre-trained models are publicly available at: https://github.com/maryam089/SDViT