 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearID: Identity Representation Learning via Near-identity Distractors
Apr 02, 2026When evaluating identity-focused tasks such as personalized generation and image editing, existing vision encoders entangle object identity with background context, leading to unreliable representations and metrics. We introduce the first principled framework to address this vulnerability using Near-identity (NearID) distractors, where semantically similar but distinct instances are placed on the exact same background as a reference image, eliminating contextual shortcuts and isolating identity as the sole discriminative signal. Based on this principle, we present the NearID dataset (19K identities, 316K matched-context distractors) together with a strict margin-based evaluation protocol. Under this setting, pre-trained encoders perform poorly, achieving Sample Success Rates (SSR), a strict margin-based identity discrimination metric, as low as 30.7% and often ranking distractors above true cross-view matches. We address this by learning identity-aware representations on a frozen backbone using a two-tier contrastive objective enforcing the hierarchy: same identity > NearID distractor > random negative. This improves SSR to 99.2%, enhances part-level discrimination by 28.0%, and yields stronger alignment with human judgments on DreamBench++, a human-aligned benchmark for personalization. Project page: https://gorluxor.github.io/NearID/
Mind-the-Glitch: Visual Correspondence for Detecting Inconsistencies in Subject-Driven Generation
Sep 26, 2025We propose a novel approach for disentangling visual and semantic features from the backbones of pre-trained diffusion models, enabling visual correspondence in a manner analogous to the well-established semantic correspondence. While diffusion model backbones are known to encode semantically rich features, they must also contain visual features to support their image synthesis capabilities. However, isolating these visual features is challenging due to the absence of annotated datasets. To address this, we introduce an automated pipeline that constructs image pairs with annotated semantic and visual correspondences based on existing subject-driven image generation datasets, and design a contrastive architecture to separate the two feature types. Leveraging the disentangled representations, we propose a new metric, Visual Semantic Matching (VSM), that quantifies visual inconsistencies in subject-driven image generation. Empirical results show that our approach outperforms global feature-based metrics such as CLIP, DINO, and vision--language models in quantifying visual inconsistencies while also enabling spatial localization of inconsistent regions. To our knowledge, this is the first method that supports both quantification and localization of inconsistencies in subject-driven generation, offering a valuable tool for advancing this task. Project Page:https://abdo-eldesokey.github.io/mind-the-glitch/
EditCLIP: Representation Learning for Image Editing
Mar 26, 2025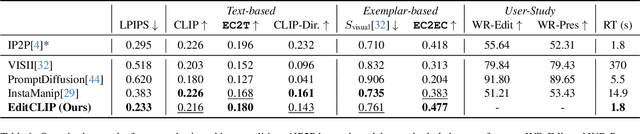
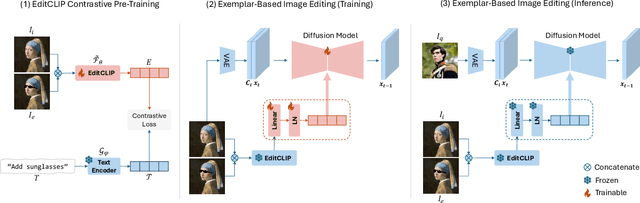

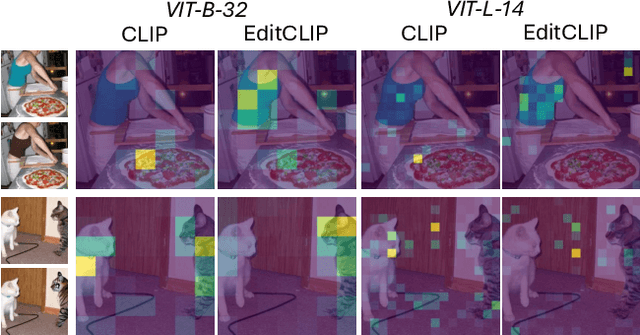
We introduce EditCLIP, a novel representation-learning approach for image editing. Our method learns a unified representation of edits by jointly encoding an input image and its edited counterpart, effectively capturing their transformation. To evaluate its effectiveness, we employ EditCLIP to solve two tasks: exemplar-based image editing and automated edit evaluation. In exemplar-based image editing, we replace text-based instructions in InstructPix2Pix with EditCLIP embeddings computed from a reference exemplar image pair. Experiments demonstrate that our approach outperforms state-of-the-art methods while being more efficient and versatile. For automated evaluation, EditCLIP assesses image edits by measuring the similarity between the EditCLIP embedding of a given image pair and either a textual editing instruction or the EditCLIP embedding of another reference image pair. Experiments show that EditCLIP aligns more closely with human judgments than existing CLIP-based metrics, providing a reliable measure of edit quality and structural preservation.
PartEdit: Fine-Grained Image Editing using Pre-Trained Diffusion Models
Feb 06, 2025



We present the first text-based image editing approach for object parts based on pre-trained diffusion models. Diffusion-based image editing approaches capitalized on the deep understanding of diffusion models of image semantics to perform a variety of edits. However, existing diffusion models lack sufficient understanding of many object parts, hindering fine-grained edits requested by users. To address this, we propose to expand the knowledge of pre-trained diffusion models to allow them to understand various object parts, enabling them to perform fine-grained edits. We achieve this by learning special textual tokens that correspond to different object parts through an efficient token optimization process. These tokens are optimized to produce reliable localization masks at each inference step to localize the editing region. Leveraging these masks, we design feature-blending and adaptive thresholding strategies to execute the edits seamlessly. To evaluate our approach, we establish a benchmark and an evaluation protocol for part editing. Experiments show that our approach outperforms existing editing methods on all metrics and is preferred by users 77-90% of the time in conducted user studies.