 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reward Functions for Cooperative Resilience in Multi-Agent Systems
Jan 29, 2026Multi-agent systems often operate in dynamic and uncertain environments, where agents must not only pursue individual goals but also safeguard collective functionality. This challenge is especially acute in mixed-motive multi-agent systems. This work focuses on cooperative resilience, the ability of agents to anticipate, resist, recover, and transform in the face of disruptions, a critical yet underexplored property in Multi-Agent Reinforcement Learning. We study how reward function design influences resilience in mixed-motive settings and introduce a novel framework that learns reward functions from ranked trajectories, guided by a cooperative resilience metric. Agents are trained in a suite of social dilemma environments using three reward strategies: i) traditional individual reward; ii) resilience-inferred reward; and iii) hybrid that balance both. We explore three reward parameterizations-linear models, hand-crafted features, and neural networks, and employ two preference-based learning algorithms to infer rewards from behavioral rankings. Our results demonstrate that hybrid strategy significantly improve robustness under disruptions without degrading task performance and reduce catastrophic outcomes like resource overuse. These findings underscore the importance of reward design in fostering resilient cooperation, and represent a step toward developing robust multi-agent systems capable of sustaining cooperation in uncertain environments.
Can LLM-Augmented autonomous agents cooperate?, An evaluation of their cooperative capabilities through Melting Pot
Mar 18, 2024As the field of AI continues to evolve, a significant dimension of this progression is the development of Large Language Models and their potential to enhance multi-agent artificial intelligence systems. This paper explores the cooperative capabilities of Large Language Model-augmented Autonomous Agents (LAAs) using the well-known Meltin Pot environments along with reference models such as GPT4 and GPT3.5. Preliminary results suggest that while these agents demonstrate a propensity for cooperation, they still struggle with effective collaboration in given environments, emphasizing the need for more robust architectures. The study's contributions include an abstraction layer to adapt Melting Pot game scenarios for LLMs, the implementation of a reusable architecture for LLM-mediated agent development - which includes short and long-term memories and different cognitive modules, and the evaluation of cooperation capabilities using a set of metrics tied to the Melting Pot's "Commons Harvest" game. The paper closes, by discussing the limitations of the current architectural framework and the potential of a new set of modules that fosters better cooperation among LAAs.
Understanding the World to Solve Social Dilemmas Using Multi-Agent Reinforcement Learning
May 19, 2023Social dilemmas are situations where groups of individuals can benefit from mutual cooperation but conflicting interests impede them from doing so. This type of situations resembles many of humanity's most critical challenges, and discovering mechanisms that facilitate the emergence of cooperative behaviors is still an open problem. In this paper, we study the behavior of self-interested rational agents that learn world models in a multi-agent reinforcement learning (RL) setting and that coexist in environments where social dilemmas can arise. Our simulation results show that groups of agents endowed with world models outperform all the other tested ones when dealing with scenarios where social dilemmas can arise. We exploit the world model architecture to qualitatively assess the learnt dynamics and confirm that each agent's world model is capable to encode information of the behavior of the changing environment and the other agent's actions. This is the first work that shows that world models facilitate the emergence of complex coordinated behaviors that enable interacting agents to ``understand'' both environmental and social dynamics.
Concept Learning in Deep Reinforcement Learning
May 19, 2020
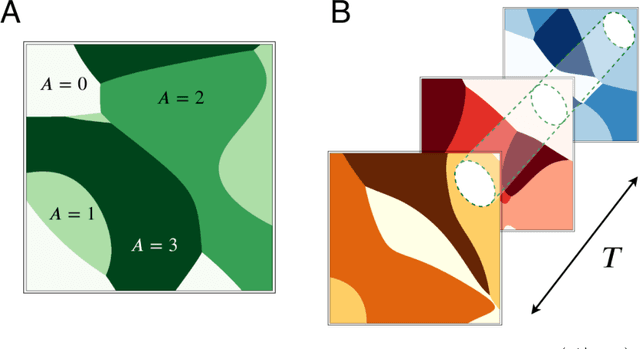


Deep reinforcement learning techniques have shown to be a promising path to solve very complex tasks that once were thought to be out of the realm of machines. However, while humans and animals learn incrementally during their lifetimes and exploit their experience to solve new tasks, standard deep learning methods specialize to solve only one task at a time and whatever information they acquire is hardly reusable in new situations. Given that any artificial agent would need such a generalization ability to deal with the complexities of the world, it is critical to understand what mechanisms give rise to this ability. We argue that one of the mechanisms humans rely on is the use of discrete conceptual representations to encode their sensory inputs. These representations group similar inputs in such a way that combined they provide a level of abstraction that is transverse to a wide variety of tasks, filtering out irrelevant information for their solution. Here, we show that it is possible to learn such concept-like representations by self-supervision, following an information-bottleneck approach, and that these representations accelerate the transference of skills by providing a prior that guides the policy optimization process. Our method is able to learn useful concepts in locomotive tasks that significantly reduce the number of optimization steps required, opening a new path to endow artificial agents with generalization abilities.