 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$ abla τ$: Gradient-based and Task-Agnostic machine Unlearning
Mar 21, 2024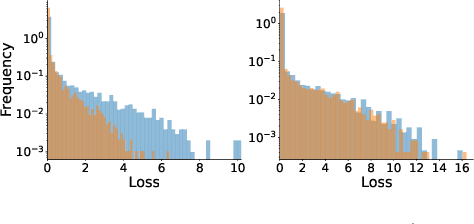
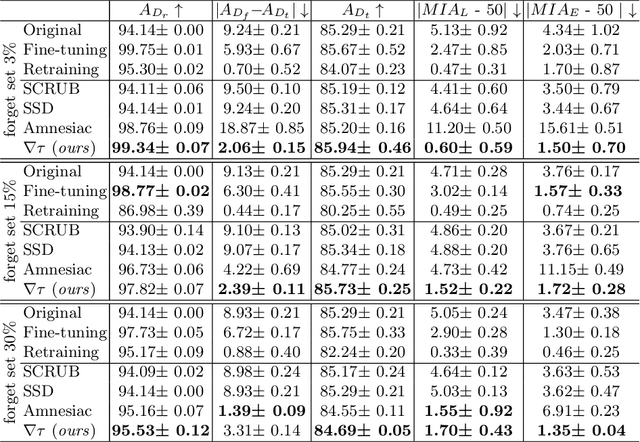
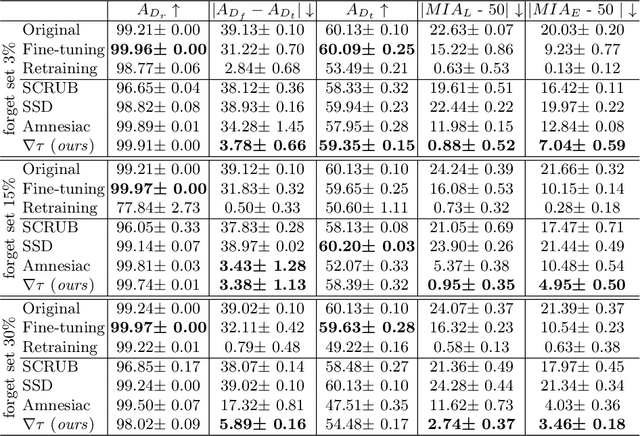
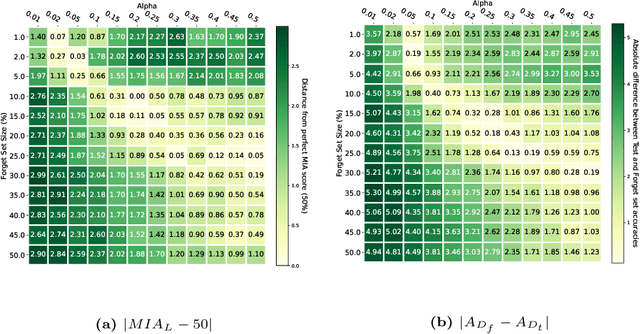
Machine Unlearning, the process of selectively eliminating the influence of certain data examples used during a model's training, has gained significant attention as a means for practitioners to comply with recent data protection regulations. However, existing unlearning methods face critical drawbacks, including their prohibitively high cost, often associated with a large number of hyperparameters, and the limitation of forgetting only relatively small data portions. This often makes retraining the model from scratch a quicker and more effective solution. In this study, we introduce Gradient-based and Task-Agnostic machine Unlearning ($\nabla \tau$), an optimization framework designed to remove the influence of a subset of training data efficiently. It applies adaptive gradient ascent to the data to be forgotten while using standard gradient descent for the remaining data. $\nabla \tau$ offers multiple benefits over existing approaches. It enables the unlearning of large sections of the training dataset (up to 30%). It is versatile, supporting various unlearning tasks (such as subset forgetting or class removal) and applicable across different domains (images, text, etc.). Importantly, $\nabla \tau$ requires no hyperparameter adjustments, making it a more appealing option than retraining the model from scratch. We evaluate our framework's effectiveness using a set of well-established Membership Inference Attack metrics, demonstrating up to 10% enhancements in performance compared to state-of-the-art methods without compromising the original model's accuracy.