 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse Synthetic Datasets for Evaluation of Real-life Recommender Systems
Nov 27, 2024



Synthetic datasets are important for evaluating and testing machine learning models. When evaluating real-life recommender systems, high-dimensional categorical (and sparse) datasets are often considered. Unfortunately, there are not many solutions that would allow generation of artificial datasets with such characteristics. For that purpose, we developed a novel framework for generating synthetic datasets that are diverse and statistically coherent. Our framework allows for creation of datasets with controlled attributes, enabling iterative modifications to fit specific experimental needs, such as introducing complex feature interactions, feature cardinality, or specific distributions. We demonstrate the framework's utility through use cases such as benchmarking probabilistic counting algorithms, detecting algorithmic bias, and simulating AutoML searches. Unlike existing methods that either focus narrowly on specific dataset structures, or prioritize (private) data synthesis through real data, our approach provides a modular means to quickly generating completely synthetic datasets we can tailor to diverse experimental requirements. Our results show that the framework effectively isolates model behavior in unique situations and highlights its potential for significant advancements in the evaluation and development of recommender systems. The readily-available framework is available as a free open Python package to facilitate research with minimal friction.
Prevalent Frequency of Emotional and Physical Symptoms in Social Anxiety using Zero Shot Classification: An Observational Study
Apr 26, 2024Social anxiety represents a prevalent challenge in modern society, affecting individuals across personal and professional spheres. Left unaddressed, this condition can yield substantial negative consequences, impacting social interactions and performance. Further understanding its diverse physical and emotional symptoms becomes pivotal for comprehensive diagnosis and tailored therapeutic interventions. This study analyze prevalence and frequency of social anxiety symptoms taken from Mayo Clinic, exploring diverse human experiences from utilizing a large Reddit dataset dedicated to this issue. Leveraging these platforms, the research aims to extract insights and examine a spectrum of physical and emotional symptoms linked to social anxiety disorder. Upholding ethical considerations, the study maintains strict user anonymity within the dataset. By employing a novel approach, the research utilizes BART-based multi-label zero-shot classification to identify and measure symptom prevalence and significance in the form of probability score for each symptom under consideration. Results uncover distinctive patterns: "Trembling" emerges as a prevalent physical symptom, while emotional symptoms like "Fear of being judged negatively" exhibit high frequencies. These findings offer insights into the multifaceted nature of social anxiety, aiding clinical practices and interventions tailored to its diverse expressions.
Zero-Shot Reasoning: Personalized Content Generation Without the Cold Start Problem
Feb 15, 2024Procedural content generation uses algorithmic techniques to create large amounts of new content for games at much lower production costs. In newer approaches, procedural content generation utilizes machine learning. However, these methods usually require expensive collection of large amounts of data, as well as the development and training of fairly complex learning models, which can be both extremely time-consuming and expensive. The core of our research is to explore whether we can lower the barrier to the use of personalized procedural content generation through a more practical and generalizable approach with large language models. Matching game content with player preferences benefits both players, who enjoy the game more, and developers, who increasingly depend on players enjoying the game before being able to monetize it. Therefore, this paper presents a novel approach to achieving personalization by using large language models to propose levels based on the gameplay data continuously collected from individual players. We compared the levels generated using our approach with levels generated with more traditional procedural generation techniques. Our easily reproducible method has proven viable in a production setting and outperformed levels generated by traditional methods in the probability that a player will not quit the game mid-level.
Feature embedding in click-through rate prediction
Sep 20, 2022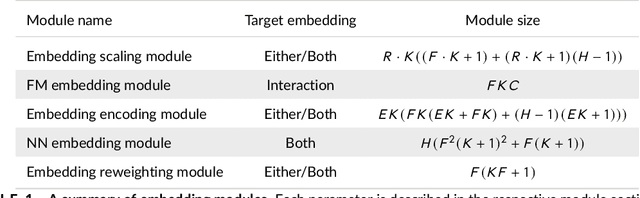
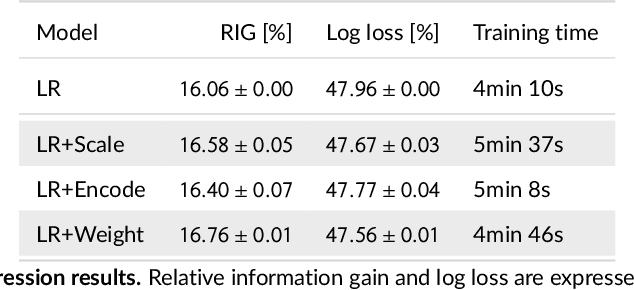
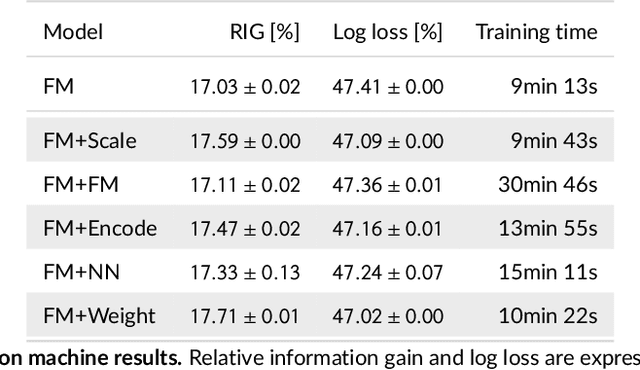
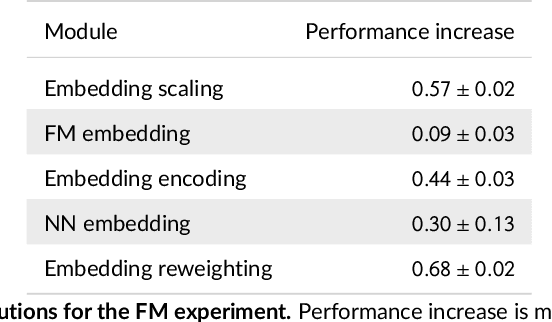
We tackle the challenge of feature embedding for the purposes of improving the click-through rate prediction process. We select three models: logistic regression, factorization machines and deep factorization machines, as our baselines and propose five different feature embedding modules: embedding scaling, FM embedding, embedding encoding, NN embedding and the embedding reweighting module. The embedding modules act as a way to improve baseline model feature embeddings and are trained alongside the rest of the model parameters in an end-to-end manner. Each module is individually added to a baseline model to obtain a new augmented model. We test the predictive performance of our augmented models on a publicly accessible dataset used for benchmarking click-through rate prediction models. Our results show that several proposed embedding modules provide an important increase in predictive performance without a drastic increase in training time.
Predicting the Popularity of Games on Steam
Oct 06, 2021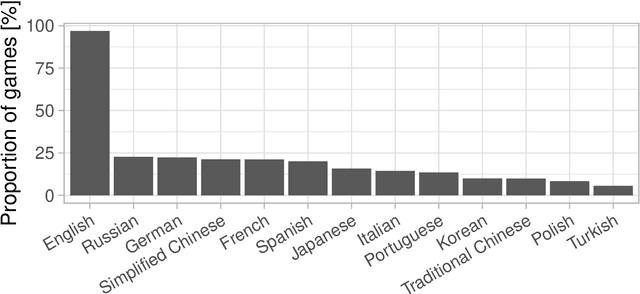

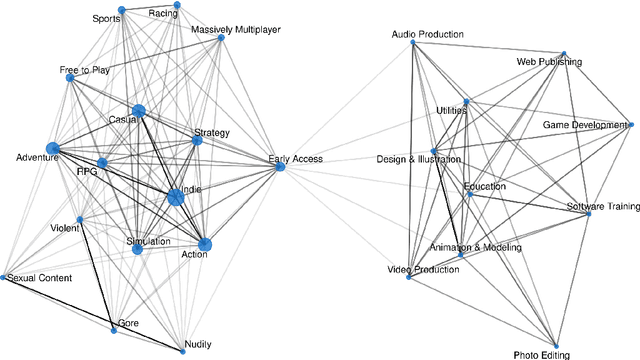
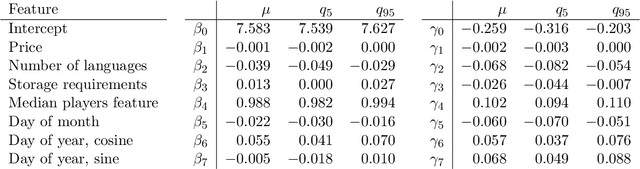
The video game industry has seen rapid growth over the last decade. Thousands of video games are released and played by millions of people every year, creating a large community of players. Steam is a leading gaming platform and social networking site, which allows its users to purchase and store games. A by-product of Steam is a large database of information about games, players, and gaming behavior. In this paper, we take recent video games released on Steam and aim to discover the relation between game popularity and a game's features that can be acquired through Steam. We approach this task by predicting the popularity of Steam games in the early stages after their release and we use a Bayesian approach to understand the influence of a game's price, size, supported languages, release date, and genres on its player count. We implement several models and discover that a genre-based hierarchical approach achieves the best performance. We further analyze the model and interpret its coefficients, which indicate that games released at the beginning of the month and games of certain genres correlate with game popularity.