 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bag of Tricks for Scaling CPU-based Deep FFMs to more than 300m Predictions per Second
Jul 14, 2024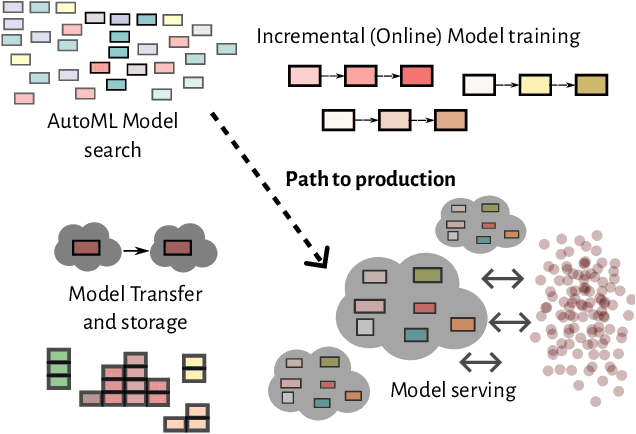
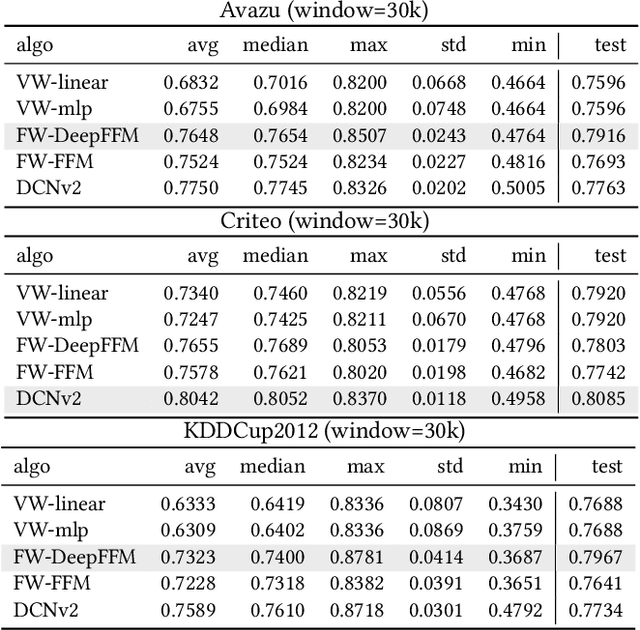
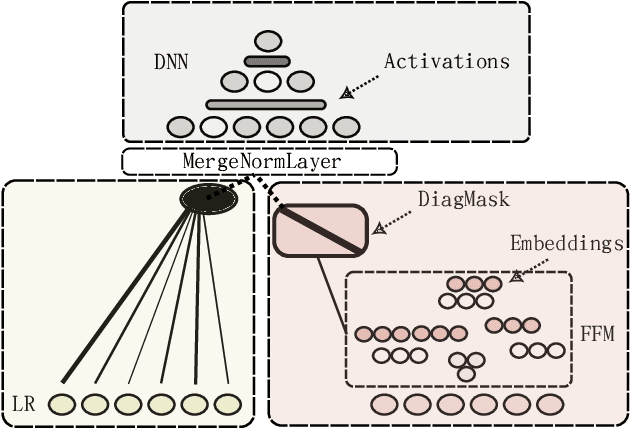

Field-aware Factorization Machines (FFMs) have emerged as a powerful model for click-through rate prediction, particularly excelling in capturing complex feature interactions. In this work, we present an in-depth analysis of our in-house, Rust-based Deep FFM implementation, and detail its deployment on a CPU-only, multi-data-center scale. We overview key optimizations devised for both training and inference, demonstrated by previously unpublished benchmark results in efficient model search and online training. Further, we detail an in-house weight quantization that resulted in more than an order of magnitude reduction in bandwidth footprint related to weight transfers across data-centres. We disclose the engine and associated techniques under an open-source license to contribute to the broader machine learning community. This paper showcases one of the first successful CPU-only deployments of Deep FFMs at such scale, marking a significant stride in practical, low-footprint click-through rate prediction methodologies.
Drifter: Efficient Online Feature Monitoring for Improved Data Integrity in Large-Scale Recommendation Systems
Sep 21, 2023Real-world production systems often grapple with maintaining data quality in large-scale, dynamic streams. We introduce Drifter, an efficient and lightweight system for online feature monitoring and verification in recommendation use cases. Drifter addresses limitations of existing methods by delivering agile, responsive, and adaptable data quality monitoring, enabling real-time root cause analysis, drift detection and insights into problematic production events. Integrating state-of-the-art online feature ranking for sparse data and anomaly detection ideas, Drifter is highly scalable and resource-efficient, requiring only two threads and less than a gigabyte of RAM per production deployments that handle millions of instances per minute. Evaluation on real-world data sets demonstrates Drifter's effectiveness in alerting and mitigating data quality issues, substantially improving reliability and performance of real-time live recommender systems.
Unleash the Power of Context: Enhancing Large-Scale Recommender Systems with Context-Based Prediction Models
Jul 25, 2023In this work, we introduce the notion of Context-Based Prediction Models. A Context-Based Prediction Model determines the probability of a user's action (such as a click or a conversion) solely by relying on user and contextual features, without considering any specific features of the item itself. We have identified numerous valuable applications for this modeling approach, including training an auxiliary context-based model to estimate click probability and incorporating its prediction as a feature in CTR prediction models. Our experiments indicate that this enhancement brings significant improvements in offline and online business metrics while having minimal impact on the cost of serving. Overall, our work offers a simple and scalable, yet powerful approach for enhancing the performance of large-scale commercial recommender systems, with broad implications for the field of personalized recommendations.
Dynamic Surrogate Switching: Sample-Efficient Search for Factorization Machine Configurations in Online Recommendations
Sep 29, 2022
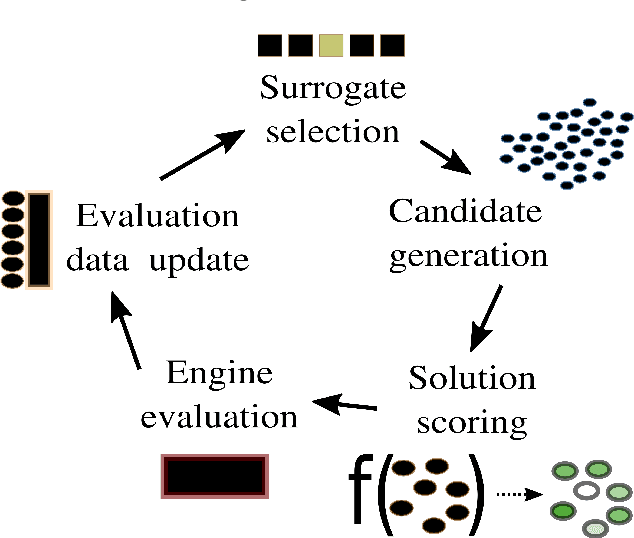
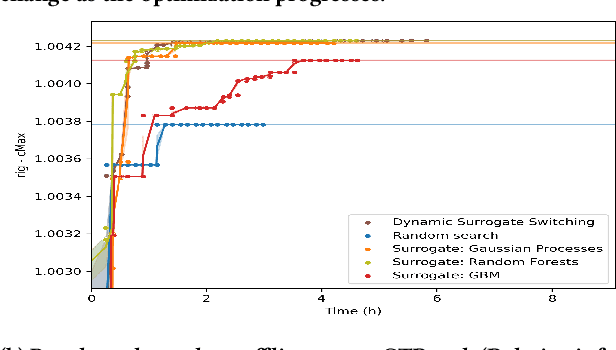
Hyperparameter optimization is the process of identifying the appropriate hyperparameter configuration of a given machine learning model with regard to a given learning task. For smaller data sets, an exhaustive search is possible; However, when the data size and model complexity increase, the number of configuration evaluations becomes the main computational bottleneck. A promising paradigm for tackling this type of problem is surrogate-based optimization. The main idea underlying this paradigm considers an incrementally updated model of the relation between the hyperparameter space and the output (target) space; the data for this model are obtained by evaluating the main learning engine, which is, for example, a factorization machine-based model. By learning to approximate the hyperparameter-target relation, the surrogate (machine learning) model can be used to score large amounts of hyperparameter configurations, exploring parts of the configuration space beyond the reach of direct machine learning engine evaluation. Commonly, a surrogate is selected prior to optimization initialization and remains the same during the search. We investigated whether dynamic switching of surrogates during the optimization itself is a sensible idea of practical relevance for selecting the most appropriate factorization machine-based models for large-scale online recommendation. We conducted benchmarks on data sets containing hundreds of millions of instances against established baselines such as Random Forest- and Gaussian process-based surrogates. The results indicate that surrogate switching can offer good performance while considering fewer learning engine evaluations.
Feature embedding in click-through rate prediction
Sep 20, 2022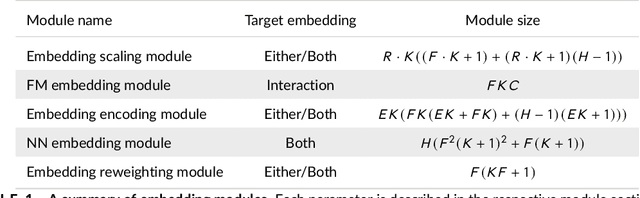
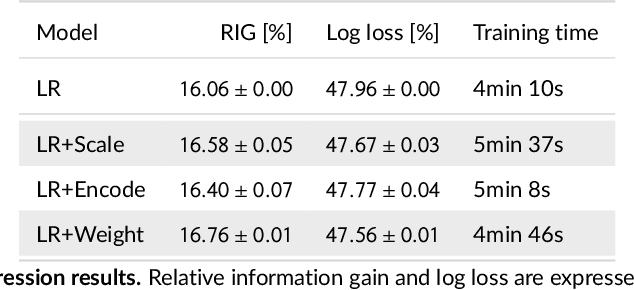
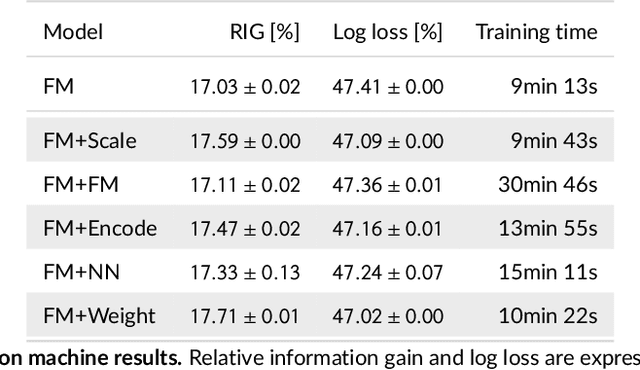
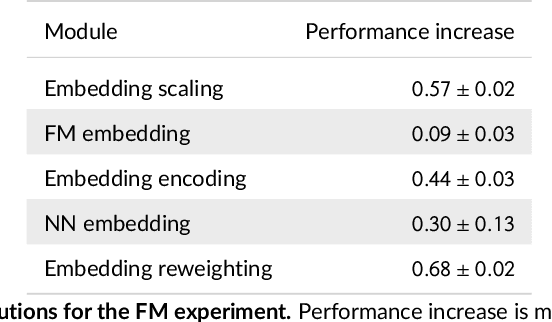
We tackle the challenge of feature embedding for the purposes of improving the click-through rate prediction process. We select three models: logistic regression, factorization machines and deep factorization machines, as our baselines and propose five different feature embedding modules: embedding scaling, FM embedding, embedding encoding, NN embedding and the embedding reweighting module. The embedding modules act as a way to improve baseline model feature embeddings and are trained alongside the rest of the model parameters in an end-to-end manner. Each module is individually added to a baseline model to obtain a new augmented model. We test the predictive performance of our augmented models on a publicly accessible dataset used for benchmarking click-through rate prediction models. Our results show that several proposed embedding modules provide an important increase in predictive performance without a drastic increase in training time.
Exploration with Model Uncertainty at Extreme Scale in Real-Time Bidding
Aug 03, 2022In this work, we present a scalable and efficient system for exploring the supply landscape in real-time bidding. The system directs exploration based on the predictive uncertainty of models used for click-through rate prediction and works in a high-throughput, low-latency environment. Through online A/B testing, we demonstrate that exploration with model uncertainty has a positive impact on model performance and business KPIs.
Scaling TensorFlow to 300 million predictions per second
Sep 20, 2021We present the process of transitioning machine learning models to the TensorFlow framework at a large scale in an online advertising ecosystem. In this talk we address the key challenges we faced and describe how we successfully tackled them; notably, implementing the models in TF and serving them efficiently with low latency using various optimization techniques.