 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bag of Tricks for Scaling CPU-based Deep FFMs to more than 300m Predictions per Second
Jul 14, 2024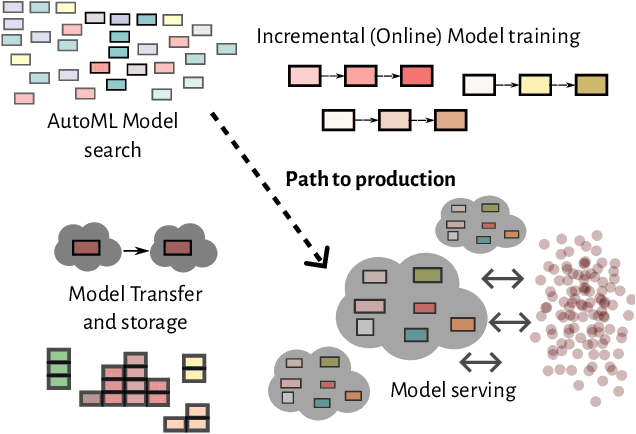
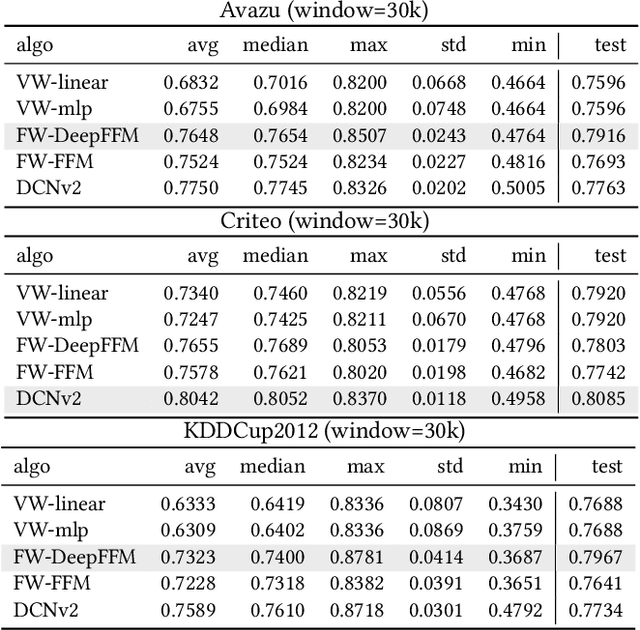
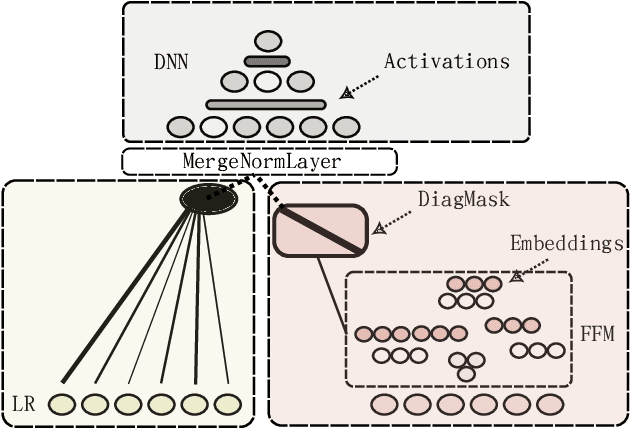

Field-aware Factorization Machines (FFMs) have emerged as a powerful model for click-through rate prediction, particularly excelling in capturing complex feature interactions. In this work, we present an in-depth analysis of our in-house, Rust-based Deep FFM implementation, and detail its deployment on a CPU-only, multi-data-center scale. We overview key optimizations devised for both training and inference, demonstrated by previously unpublished benchmark results in efficient model search and online training. Further, we detail an in-house weight quantization that resulted in more than an order of magnitude reduction in bandwidth footprint related to weight transfers across data-centres. We disclose the engine and associated techniques under an open-source license to contribute to the broader machine learning community. This paper showcases one of the first successful CPU-only deployments of Deep FFMs at such scale, marking a significant stride in practical, low-footprint click-through rate prediction methodologies.
Dynamic Surrogate Switching: Sample-Efficient Search for Factorization Machine Configurations in Online Recommendations
Sep 29, 2022
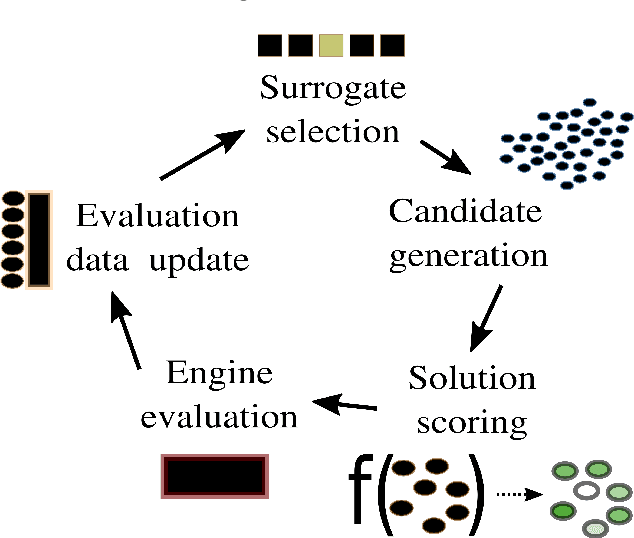
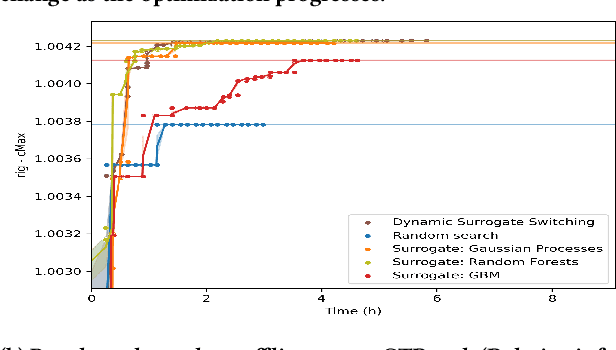
Hyperparameter optimization is the process of identifying the appropriate hyperparameter configuration of a given machine learning model with regard to a given learning task. For smaller data sets, an exhaustive search is possible; However, when the data size and model complexity increase, the number of configuration evaluations becomes the main computational bottleneck. A promising paradigm for tackling this type of problem is surrogate-based optimization. The main idea underlying this paradigm considers an incrementally updated model of the relation between the hyperparameter space and the output (target) space; the data for this model are obtained by evaluating the main learning engine, which is, for example, a factorization machine-based model. By learning to approximate the hyperparameter-target relation, the surrogate (machine learning) model can be used to score large amounts of hyperparameter configurations, exploring parts of the configuration space beyond the reach of direct machine learning engine evaluation. Commonly, a surrogate is selected prior to optimization initialization and remains the same during the search. We investigated whether dynamic switching of surrogates during the optimization itself is a sensible idea of practical relevance for selecting the most appropriate factorization machine-based models for large-scale online recommendation. We conducted benchmarks on data sets containing hundreds of millions of instances against established baselines such as Random Forest- and Gaussian process-based surrogates. The results indicate that surrogate switching can offer good performance while considering fewer learning engine evaluations.