 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Surrogate Switching: Sample-Efficient Search for Factorization Machine Configurations in Online Recommendations
Sep 29, 2022
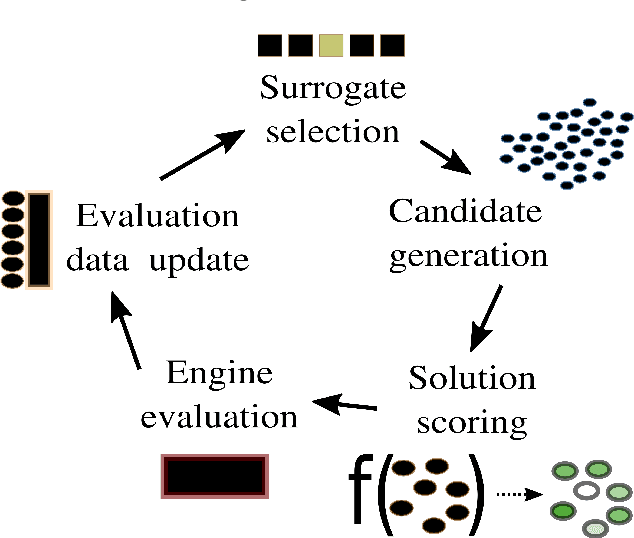
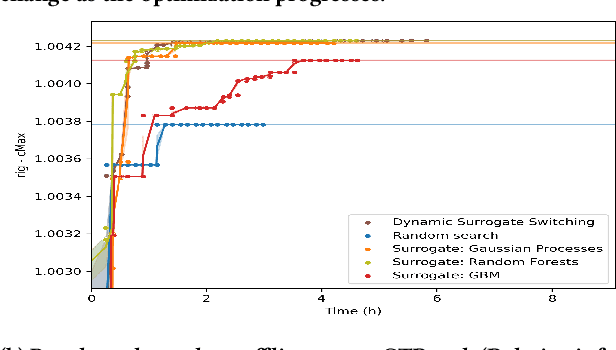
Hyperparameter optimization is the process of identifying the appropriate hyperparameter configuration of a given machine learning model with regard to a given learning task. For smaller data sets, an exhaustive search is possible; However, when the data size and model complexity increase, the number of configuration evaluations becomes the main computational bottleneck. A promising paradigm for tackling this type of problem is surrogate-based optimization. The main idea underlying this paradigm considers an incrementally updated model of the relation between the hyperparameter space and the output (target) space; the data for this model are obtained by evaluating the main learning engine, which is, for example, a factorization machine-based model. By learning to approximate the hyperparameter-target relation, the surrogate (machine learning) model can be used to score large amounts of hyperparameter configurations, exploring parts of the configuration space beyond the reach of direct machine learning engine evaluation. Commonly, a surrogate is selected prior to optimization initialization and remains the same during the search. We investigated whether dynamic switching of surrogates during the optimization itself is a sensible idea of practical relevance for selecting the most appropriate factorization machine-based models for large-scale online recommendation. We conducted benchmarks on data sets containing hundreds of millions of instances against established baselines such as Random Forest- and Gaussian process-based surrogates. The results indicate that surrogate switching can offer good performance while considering fewer learning engine evaluations.