 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical evaluation of normalizing flows in Markov Chain Monte Carlo
Dec 22, 2024Recent advances in MCMC use normalizing flows to precondition target distributions and enable jumps to distant regions. However, there is currently no systematic comparison of different normalizing flow architectures for MCMC. As such, many works choose simple flow architectures that are readily available and do not consider other models. Guidelines for choosing an appropriate architecture would reduce analysis time for practitioners and motivate researchers to take the recommended models as foundations to be improved. We provide the first such guideline by extensively evaluating many normalizing flow architectures on various flow-based MCMC methods and target distributions. When the target density gradient is available, we show that flow-based MCMC outperforms classic MCMC for suitable NF architecture choices with minor hyperparameter tuning. When the gradient is unavailable, flow-based MCMC wins with off-the-shelf architectures. We find contractive residual flows to be the best general-purpose models with relatively low sensitivity to hyperparameter choice. We also provide various insights into normalizing flow behavior within MCMC when varying their hyperparameters, properties of target distributions, and the overall computational budget.
Benchmarking the Fidelity and Utility of Synthetic Relational Data
Oct 04, 2024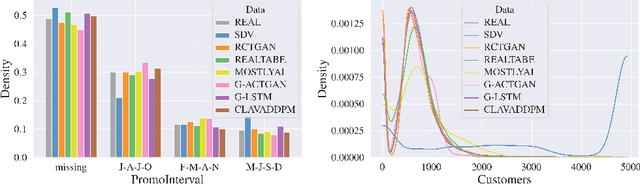
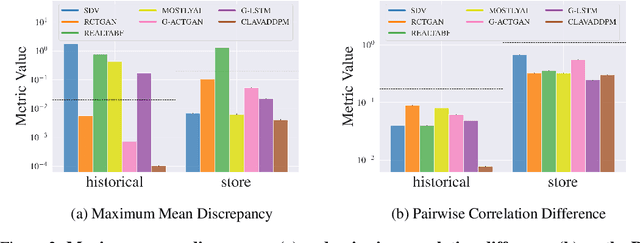
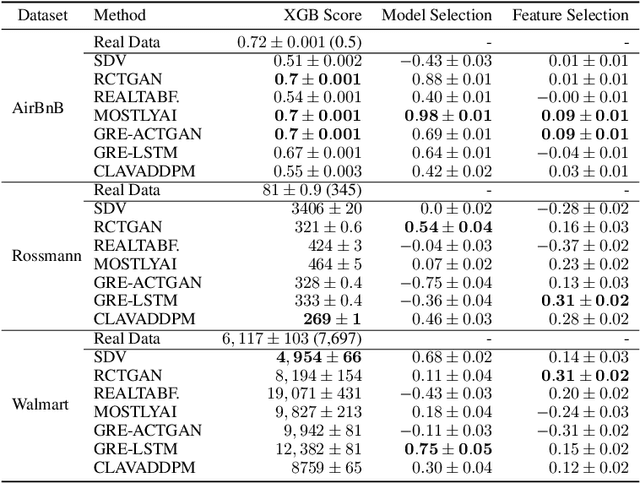
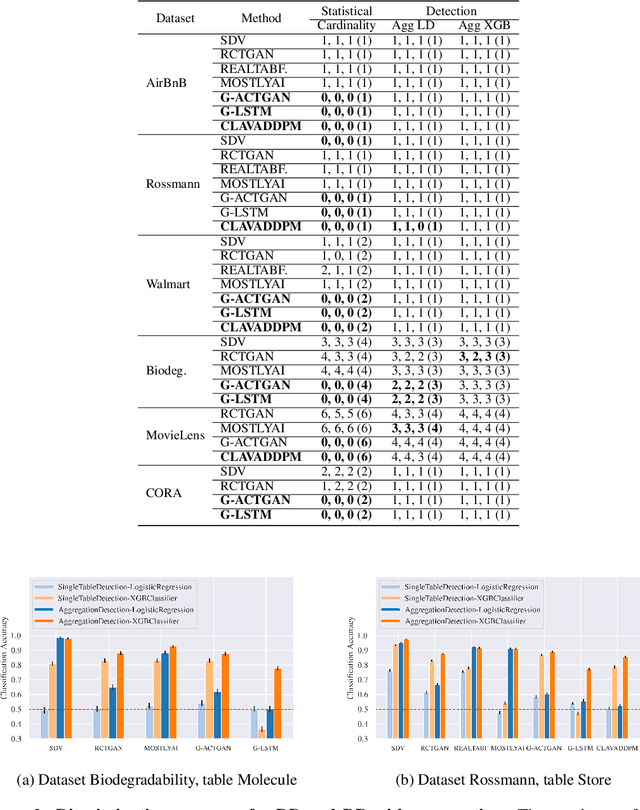
Synthesizing relational data has started to receive more attention from researchers, practitioners, and industry. The task is more difficult than synthesizing a single table due to the added complexity of relationships between tables. For the same reason, benchmarking methods for synthesizing relational data introduces new challenges. Our work is motivated by a lack of an empirical evaluation of state-of-the-art methods and by gaps in the understanding of how such an evaluation should be done. We review related work on relational data synthesis, common benchmarking datasets, and approaches to measuring the fidelity and utility of synthetic data. We combine the best practices and a novel robust detection approach into a benchmarking tool and use it to compare six methods, including two commercial tools. While some methods are better than others, no method is able to synthesize a dataset that is indistinguishable from original data. For utility, we typically observe moderate correlation between real and synthetic data for both model predictive performance and feature importance.
Predicting the Popularity of Games on Steam
Oct 06, 2021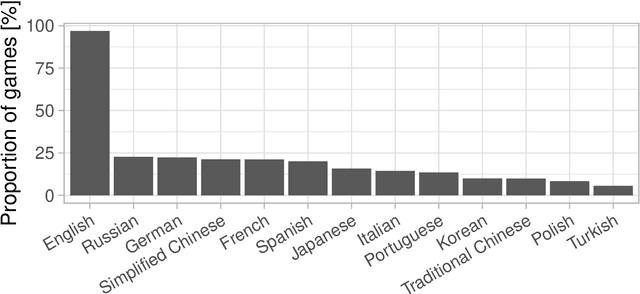

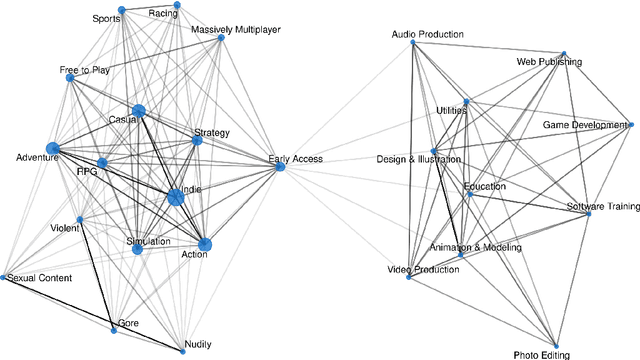
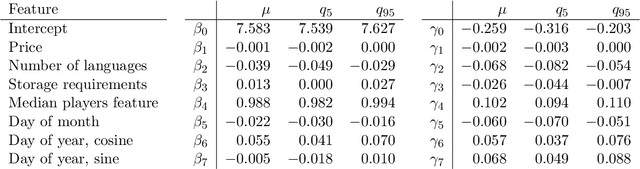
The video game industry has seen rapid growth over the last decade. Thousands of video games are released and played by millions of people every year, creating a large community of players. Steam is a leading gaming platform and social networking site, which allows its users to purchase and store games. A by-product of Steam is a large database of information about games, players, and gaming behavior. In this paper, we take recent video games released on Steam and aim to discover the relation between game popularity and a game's features that can be acquired through Steam. We approach this task by predicting the popularity of Steam games in the early stages after their release and we use a Bayesian approach to understand the influence of a game's price, size, supported languages, release date, and genres on its player count. We implement several models and discover that a genre-based hierarchical approach achieves the best performance. We further analyze the model and interpret its coefficients, which indicate that games released at the beginning of the month and games of certain genres correlate with game popularity.