 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Fidelity and Utility of Synthetic Relational Data
Paper and Code
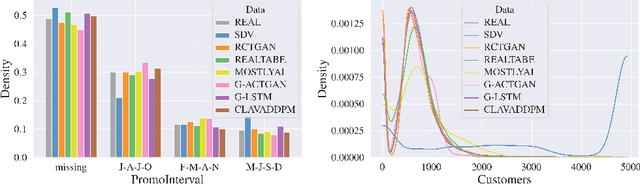
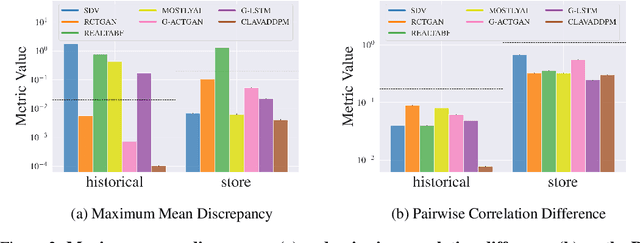
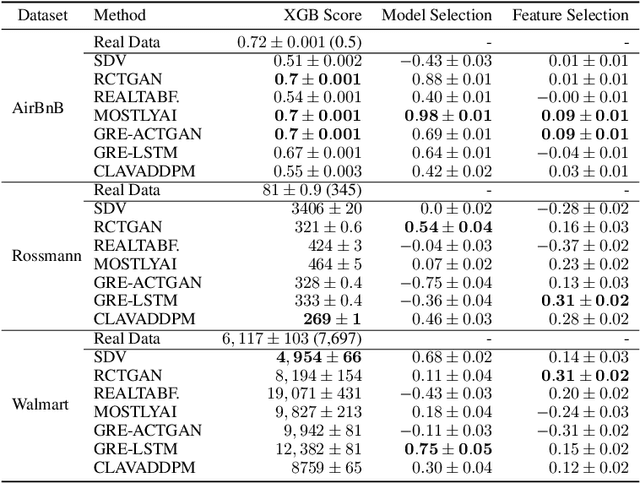
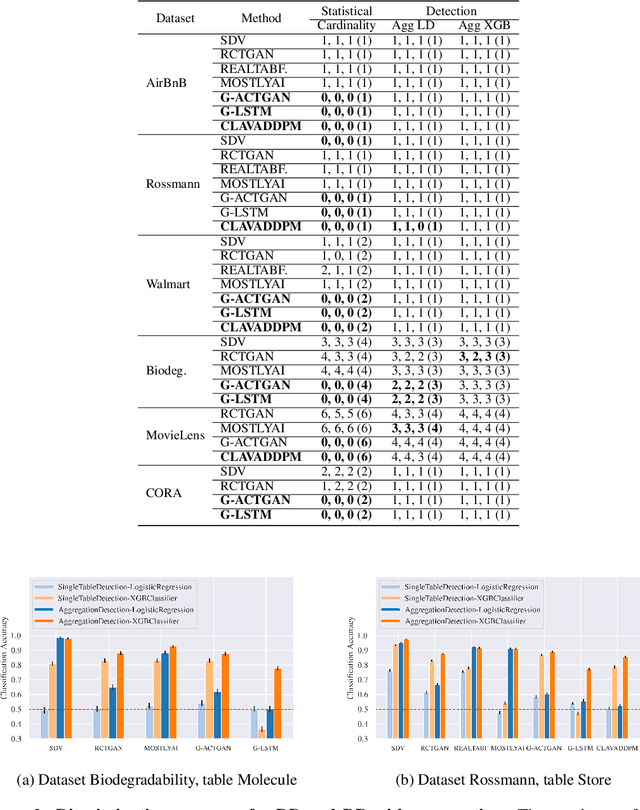
Synthesizing relational data has started to receive more attention from researchers, practitioners, and industry. The task is more difficult than synthesizing a single table due to the added complexity of relationships between tables. For the same reason, benchmarking methods for synthesizing relational data introduces new challenges. Our work is motivated by a lack of an empirical evaluation of state-of-the-art methods and by gaps in the understanding of how such an evaluation should be done. We review related work on relational data synthesis, common benchmarking datasets, and approaches to measuring the fidelity and utility of synthetic data. We combine the best practices and a novel robust detection approach into a benchmarking tool and use it to compare six methods, including two commercial tools. While some methods are better than others, no method is able to synthesize a dataset that is indistinguishable from original data. For utility, we typically observe moderate correlation between real and synthetic data for both model predictive performance and feature importance.