 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePluRel: Synthetic Data unlocks Scaling Laws for Relational Foundation Models
Feb 03, 2026Relational Foundation Models (RFMs) facilitate data-driven decision-making by learning from complex multi-table databases. However, the diverse relational databases needed to train such models are rarely public due to privacy constraints. While there are methods to generate synthetic tabular data of arbitrary size, incorporating schema structure and primary--foreign key connectivity for multi-table generation remains challenging. Here we introduce PluRel, a framework to synthesize multi-tabular relational databases from scratch. In a step-by-step fashion, PluRel models (1) schemas with directed graphs, (2) inter-table primary-foreign key connectivity with bipartite graphs, and, (3) feature distributions in tables via conditional causal mechanisms. The design space across these stages supports the synthesis of a wide range of diverse databases, while being computationally lightweight. Using PluRel, we observe for the first time that (1) RFM pretraining loss exhibits power-law scaling with the number of synthetic databases and total pretraining tokens, (2) scaling the number of synthetic databases improves generalization to real databases, and (3) synthetic pretraining yields strong base models for continued pretraining on real databases. Overall, our framework and results position synthetic data scaling as a promising paradigm for RFMs.
Benchmarking the Fidelity and Utility of Synthetic Relational Data
Oct 04, 2024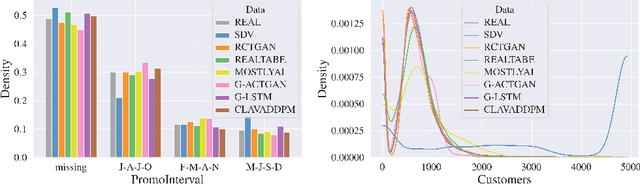
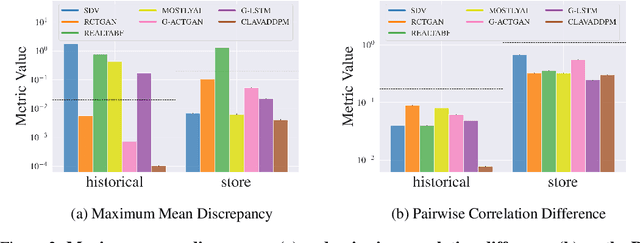
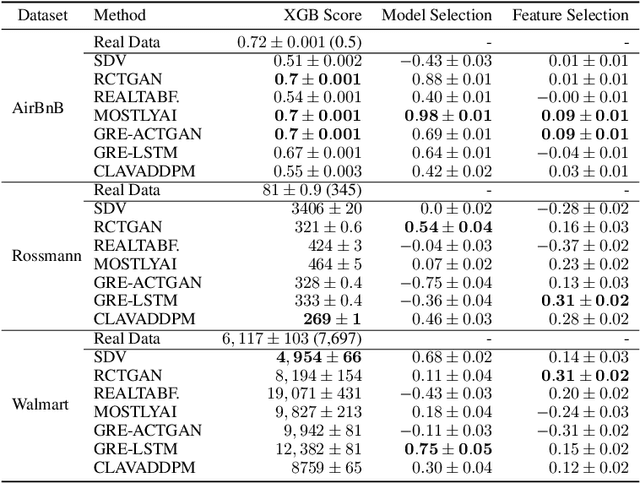
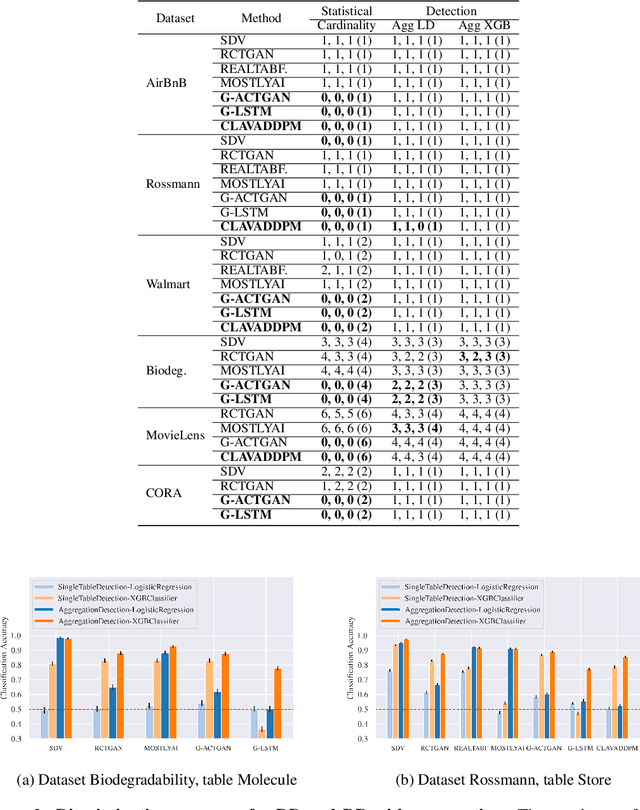
Synthesizing relational data has started to receive more attention from researchers, practitioners, and industry. The task is more difficult than synthesizing a single table due to the added complexity of relationships between tables. For the same reason, benchmarking methods for synthesizing relational data introduces new challenges. Our work is motivated by a lack of an empirical evaluation of state-of-the-art methods and by gaps in the understanding of how such an evaluation should be done. We review related work on relational data synthesis, common benchmarking datasets, and approaches to measuring the fidelity and utility of synthetic data. We combine the best practices and a novel robust detection approach into a benchmarking tool and use it to compare six methods, including two commercial tools. While some methods are better than others, no method is able to synthesize a dataset that is indistinguishable from original data. For utility, we typically observe moderate correlation between real and synthetic data for both model predictive performance and feature importance.