 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-augmented code completion for local projects using large language models
Paper and Code
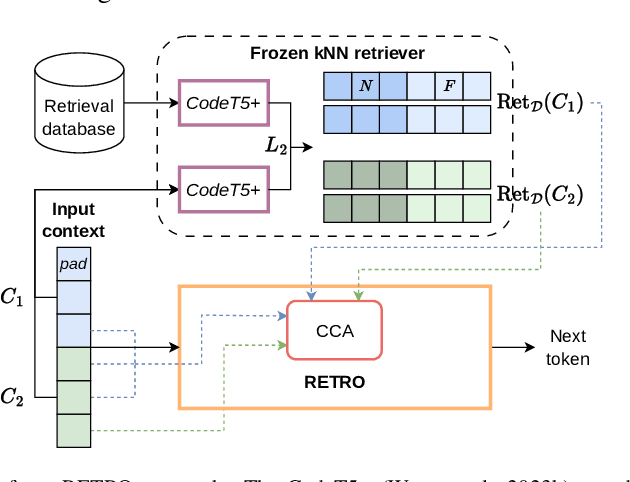
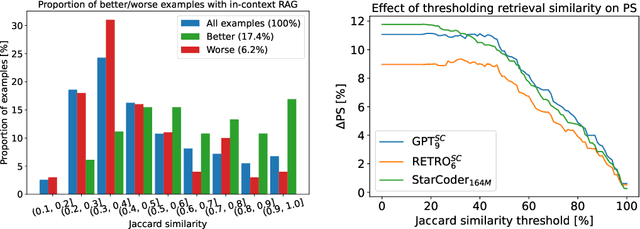
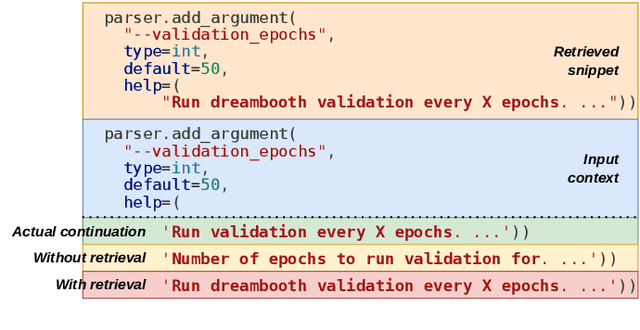

The use of large language models (LLMs) is becoming increasingly widespread among software developers. However, privacy and computational requirements are problematic with commercial solutions and the use of LLMs. In this work, we focus on using LLMs with around 160 million parameters that are suitable for local execution and augmentation with retrieval from local projects. We train two models based on the transformer architecture, the generative model GPT-2 and the retrieval-adapted RETRO model, on open-source Python files, and empirically evaluate and compare them, confirming the benefits of vector embedding based retrieval. Further, we improve our models' performance with In-context retrieval-augmented generation, which retrieves code snippets based on the Jaccard similarity of tokens. We evaluate In-context retrieval-augmented generation on larger models and conclude that, despite its simplicity, the approach is more suitable than using the RETRO architecture. We highlight the key role of proper tokenization in achieving the full potential of LLMs in code completion.