 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Word-Sense Disambiguation and Word-Sense Induction with Dictionary Examples
Mar 06, 2025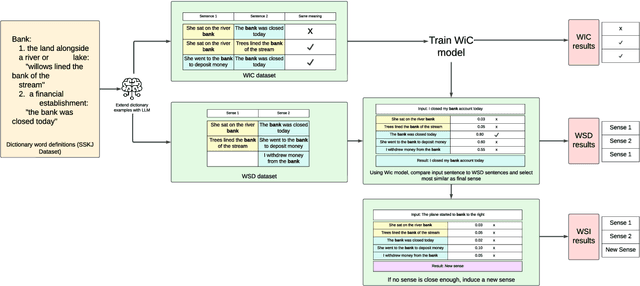



Many less-resourced languages struggle with a lack of large, task-specific datasets that are required for solving relevant tasks with modern transformer-based large language models (LLMs). On the other hand, many linguistic resources, such as dictionaries, are rarely used in this context despite their large information contents. We show how LLMs can be used to extend existing language resources in less-resourced languages for two important tasks: word-sense disambiguation (WSD) and word-sense induction (WSI). We approach the two tasks through the related but much more accessible word-in-context (WiC) task where, given a pair of sentences and a target word, a classification model is tasked with predicting whether the sense of a given word differs between sentences. We demonstrate that a well-trained model for this task can distinguish between different word senses and can be adapted to solve the WSD and WSI tasks. The advantage of using the WiC task, instead of directly predicting senses, is that the WiC task does not need pre-constructed sense inventories with a sufficient number of examples for each sense, which are rarely available in less-resourced languages. We show that sentence pairs for the WiC task can be successfully generated from dictionary examples using LLMs. The resulting prediction models outperform existing models on WiC, WSD, and WSI tasks. We demonstrate our methodology on the Slovene language, where a monolingual dictionary is available, but word-sense resources are tiny.
MICE: Mining Idioms with Contextual Embeddings
Aug 13, 2020


Idiomatic expressions can be problematic for natural language processing applications as their meaning cannot be inferred from their constituting words. A lack of successful methodological approaches and sufficiently large datasets prevents the development of machine learning approaches for detecting idioms, especially for expressions that do not occur in the training set. We present an approach, called MICE, that uses contextual embeddings for that purpose. We present a new dataset of multi-word expressions with literal and idiomatic meanings and use it to train a classifier based on two state-of-the-art contextual word embeddings: ELMo and BERT. We show that deep neural networks using both embeddings perform much better than existing approaches, and are capable of detecting idiomatic word use, even for expressions that were not present in the training set. We demonstrate cross-lingual transfer of developed models and analyze the size of the required dataset.