 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural spell-checker: Beyond words with synthetic data generation
Oct 30, 2024Spell-checkers are valuable tools that enhance communication by identifying misspelled words in written texts. Recent improvements in deep learning, and in particular in large language models, have opened new opportunities to improve traditional spell-checkers with new functionalities that not only assess spelling correctness but also the suitability of a word for a given context. In our work, we present and compare two new spell-checkers and evaluate them on synthetic, learner, and more general-domain Slovene datasets. The first spell-checker is a traditional, fast, word-based approach, based on a morphological lexicon with a significantly larger word list compared to existing spell-checkers. The second approach uses a language model trained on a large corpus with synthetically inserted errors. We present the training data construction strategies, which turn out to be a crucial component of neural spell-checkers. Further, the proposed neural model significantly outperforms all existing spell-checkers for Slovene in both precision and recall.
Generative Model for Less-Resourced Language with 1 billion parameters
Oct 09, 2024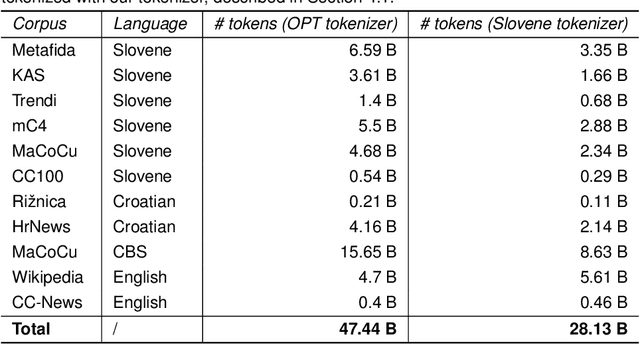
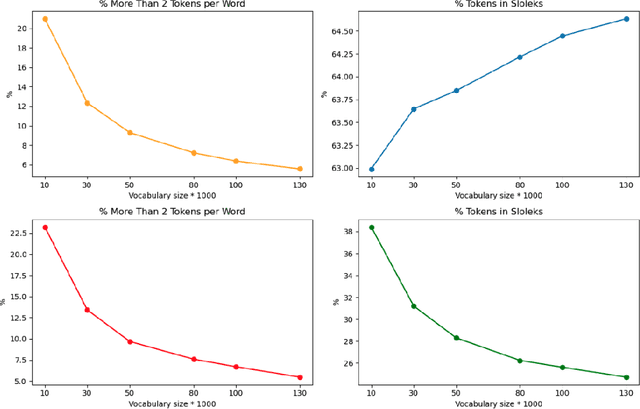
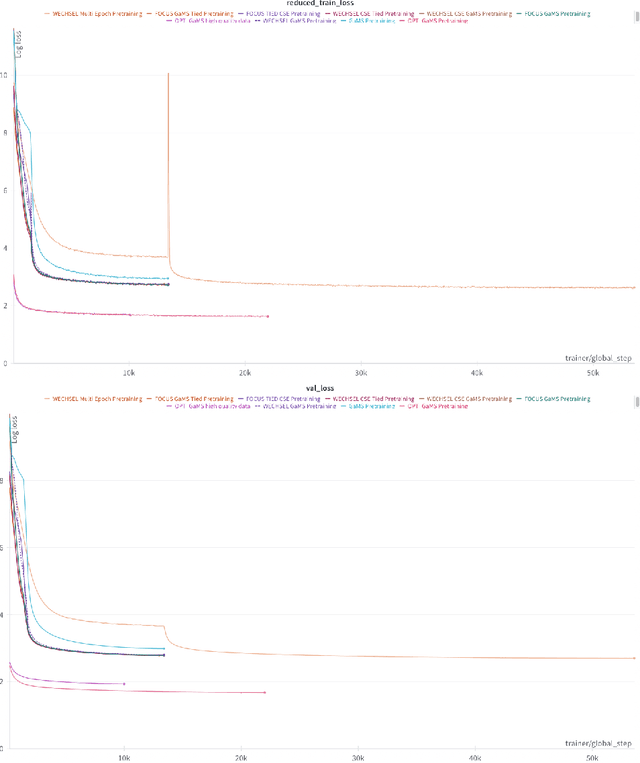
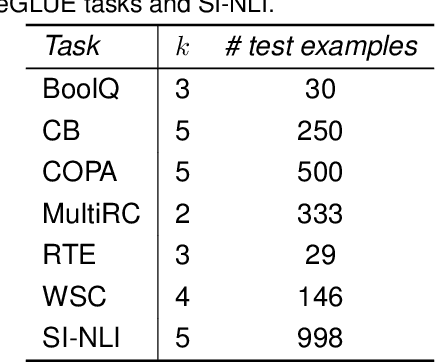
Large language models (LLMs) are a basic infrastructure for modern natural language processing. Many commercial and open-source LLMs exist for English, e.g., ChatGPT, Llama, Falcon, and Mistral. As these models are trained on mostly English texts, their fluency and knowledge of low-resource languages and societies are superficial. We present the development of large generative language models for a less-resourced language. GaMS 1B - Generative Model for Slovene with 1 billion parameters was created by continuing pretraining of the existing English OPT model. We developed a new tokenizer adapted to Slovene, Croatian, and English languages and used embedding initialization methods FOCUS and WECHSEL to transfer the embeddings from the English OPT model. We evaluate our models on several classification datasets from the Slovene suite of benchmarks and generative sentence simplification task SENTA. We only used a few-shot in-context learning of our models, which are not yet instruction-tuned. For classification tasks, in this mode, the generative models lag behind the existing Slovene BERT-type models fine-tuned for specific tasks. On a sentence simplification task, the GaMS models achieve comparable or better performance than the GPT-3.5-Turbo model.