 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis in Finance: From Transformers Back to eXplainable Lexicons (XLex)
Jun 06, 2023



Lexicon-based sentiment analysis (SA) in finance leverages specialized, manually annotated lexicons created by human experts to extract sentiment from financial texts. Although lexicon-based methods are simple to implement and fast to operate on textual data, they require considerable manual annotation efforts to create, maintain, and update the lexicons. These methods are also considered inferior to the deep learning-based approaches, such as transformer models, which have become dominant in various NLP tasks due to their remarkable performance. However, transformers require extensive data and computational resources for both training and testing. Additionally, they involve significant prediction times, making them unsuitable for real-time production environments or systems with limited processing capabilities. In this paper, we introduce a novel methodology named eXplainable Lexicons (XLex) that combines the advantages of both lexicon-based methods and transformer models. We propose an approach that utilizes transformers and SHapley Additive exPlanations (SHAP) for explainability to learn financial lexicons. Our study presents four main contributions. Firstly, we demonstrate that transformer-aided explainable lexicons can enhance the vocabulary coverage of the benchmark Loughran-McDonald (LM) lexicon, reducing the human involvement in annotating, maintaining, and updating the lexicons. Secondly, we show that the resulting lexicon outperforms the standard LM lexicon in SA of financial datasets. Thirdly, we illustrate that the lexicon-based approach is significantly more efficient in terms of model speed and size compared to transformers. Lastly, the XLex approach is inherently more interpretable than transformer models as lexicon models rely on predefined rules, allowing for better insights into the results of SA and making the XLex approach a viable tool for financial decision-making.
Survey of NLP in Pharmacology: Methodology, Tasks, Resources, Knowledge, and Tools
Aug 22, 2022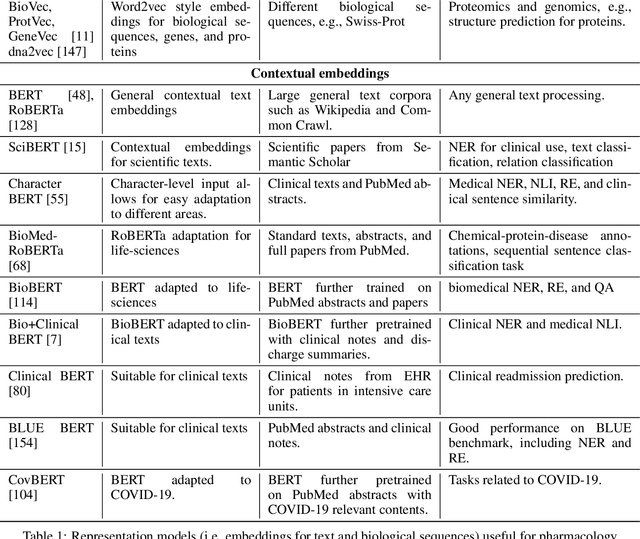
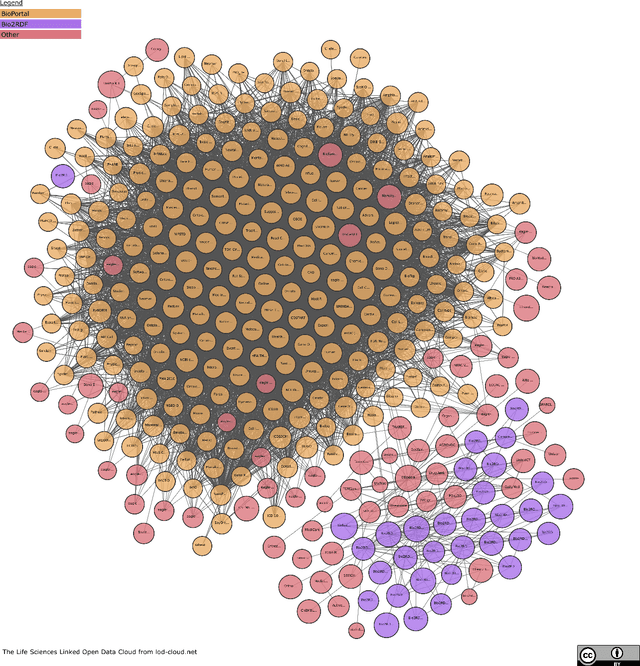

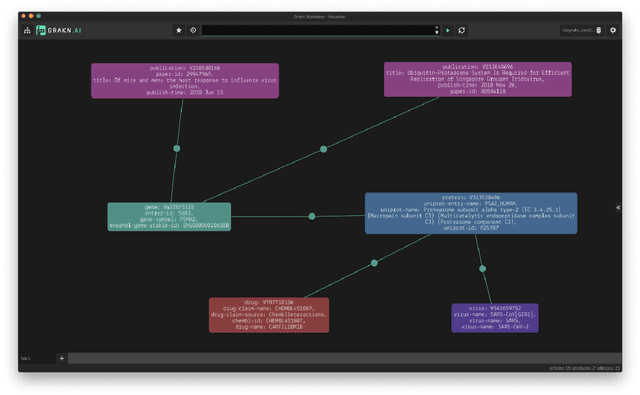
Natural language processing (NLP) is an area of artificial intelligence that applies information technologies to process the human language, understand it to a certain degree, and use it in various applications. This area has rapidly developed in the last few years and now employs modern variants of deep neural networks to extract relevant patterns from large text corpora. The main objective of this work is to survey the recent use of NLP in the field of pharmacology. As our work shows, NLP is a highly relevant information extraction and processing approach for pharmacology. It has been used extensively, from intelligent searches through thousands of medical documents to finding traces of adversarial drug interactions in social media. We split our coverage into five categories to survey modern NLP methodology, commonly addressed tasks, relevant textual data, knowledge bases, and useful programming libraries. We split each of the five categories into appropriate subcategories, describe their main properties and ideas, and summarize them in a tabular form. The resulting survey presents a comprehensive overview of the area, useful to practitioners and interested observers.
PharmKE: Knowledge Extraction Platform for Pharmaceutical Texts using Transfer Learning
Feb 25, 2021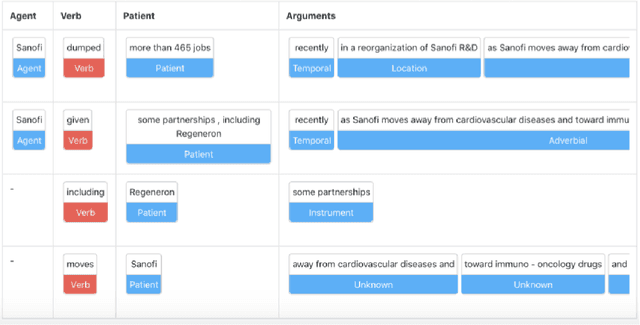
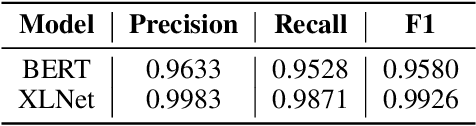
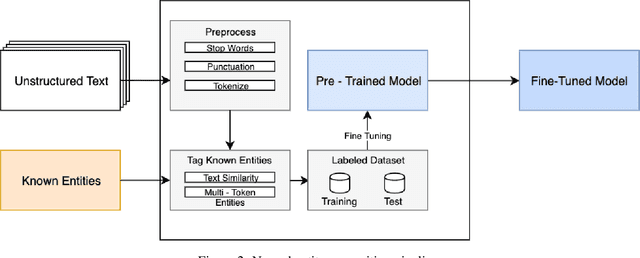
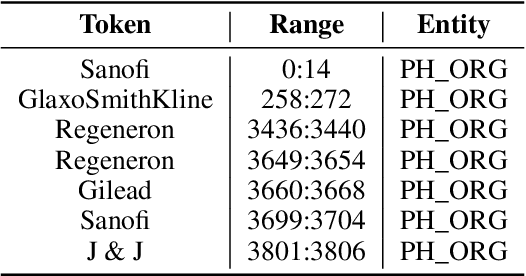
The challenge of recognizing named entities in a given text has been a very dynamic field in recent years. This is due to the advances in neural network architectures, increase of computing power and the availability of diverse labeled datasets, which deliver pre-trained, highly accurate models. These tasks are generally focused on tagging common entities, but domain-specific use-cases require tagging custom entities which are not part of the pre-trained models. This can be solved by either fine-tuning the pre-trained models, or by training custom models. The main challenge lies in obtaining reliable labeled training and test datasets, and manual labeling would be a highly tedious task. In this paper we present PharmKE, a text analysis platform focused on the pharmaceutical domain, which applies deep learning through several stages for thorough semantic analysis of pharmaceutical articles. It performs text classification using state-of-the-art transfer learning models, and thoroughly integrates the results obtained through a proposed methodology. The methodology is used to create accurately labeled training and test datasets, which are then used to train models for custom entity labeling tasks, centered on the pharmaceutical domain. The obtained results are compared to the fine-tuned BERT and BioBERT models trained on the same dataset. Additionally, the PharmKE platform integrates the results obtained from named entity recognition tasks to resolve co-references of entities and analyze the semantic relations in every sentence, thus setting up a baseline for additional text analysis tasks, such as question answering and fact extraction. The recognized entities are also used to expand the knowledge graph generated by DBpedia Spotlight for a given pharmaceutical text.