 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePharmKE: Knowledge Extraction Platform for Pharmaceutical Texts using Transfer Learning
Feb 25, 2021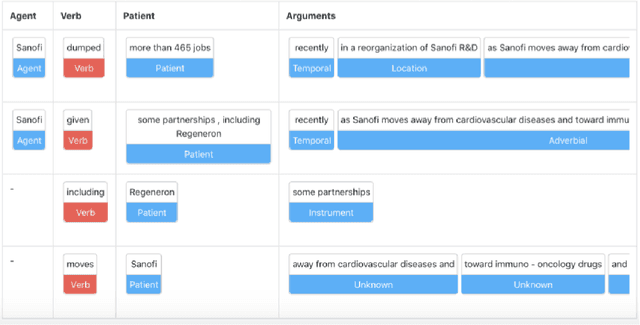
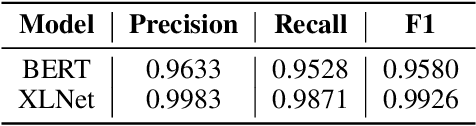
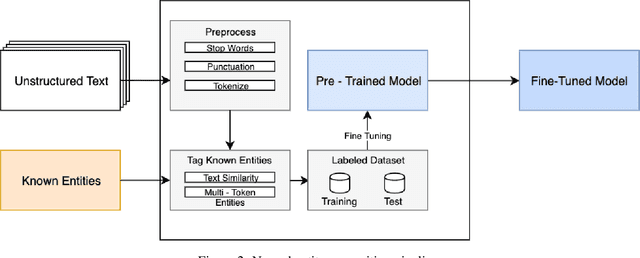
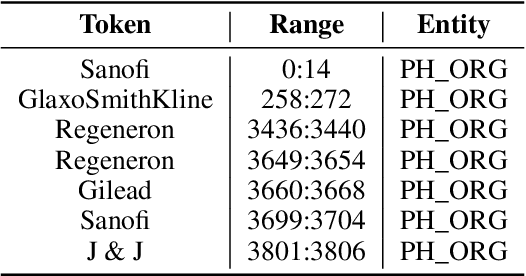
The challenge of recognizing named entities in a given text has been a very dynamic field in recent years. This is due to the advances in neural network architectures, increase of computing power and the availability of diverse labeled datasets, which deliver pre-trained, highly accurate models. These tasks are generally focused on tagging common entities, but domain-specific use-cases require tagging custom entities which are not part of the pre-trained models. This can be solved by either fine-tuning the pre-trained models, or by training custom models. The main challenge lies in obtaining reliable labeled training and test datasets, and manual labeling would be a highly tedious task. In this paper we present PharmKE, a text analysis platform focused on the pharmaceutical domain, which applies deep learning through several stages for thorough semantic analysis of pharmaceutical articles. It performs text classification using state-of-the-art transfer learning models, and thoroughly integrates the results obtained through a proposed methodology. The methodology is used to create accurately labeled training and test datasets, which are then used to train models for custom entity labeling tasks, centered on the pharmaceutical domain. The obtained results are compared to the fine-tuned BERT and BioBERT models trained on the same dataset. Additionally, the PharmKE platform integrates the results obtained from named entity recognition tasks to resolve co-references of entities and analyze the semantic relations in every sentence, thus setting up a baseline for additional text analysis tasks, such as question answering and fact extraction. The recognized entities are also used to expand the knowledge graph generated by DBpedia Spotlight for a given pharmaceutical text.