 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Agent-Driven Framework for Automated Product Knowledge Graph Construction in E-Commerce
Nov 14, 2025The rapid expansion of e-commerce platforms generates vast amounts of unstructured product data, creating significant challenges for information retrieval, recommendation systems, and data analytics. Knowledge Graphs (KGs) offer a structured, interpretable format to organize such data, yet constructing product-specific KGs remains a complex and manual process. This paper introduces a fully automated, AI agent-driven framework for constructing product knowledge graphs directly from unstructured product descriptions. Leveraging Large Language Models (LLMs), our method operates in three stages using dedicated agents: ontology creation and expansion, ontology refinement, and knowledge graph population. This agent-based approach ensures semantic coherence, scalability, and high-quality output without relying on predefined schemas or handcrafted extraction rules. We evaluate the system on a real-world dataset of air conditioner product descriptions, demonstrating strong performance in both ontology generation and KG population. The framework achieves over 97\% property coverage and minimal redundancy, validating its effectiveness and practical applicability. Our work highlights the potential of LLMs to automate structured knowledge extraction in retail, providing a scalable path toward intelligent product data integration and utilization.
* Proceedings of the 1st GOBLIN Workshop on Knowledge Graph Technologies
A Multi-Agent System for Semantic Mapping of Relational Data to Knowledge Graphs
Nov 09, 2025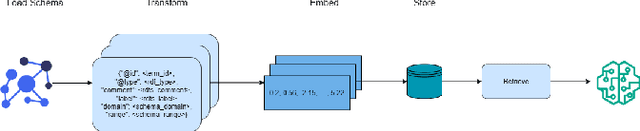
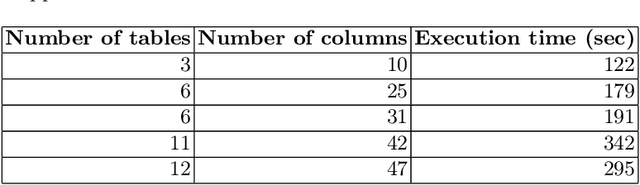
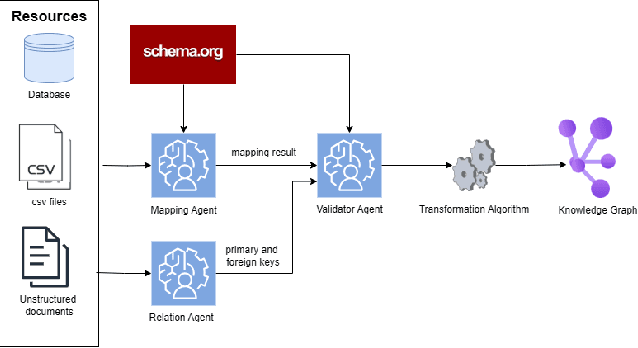
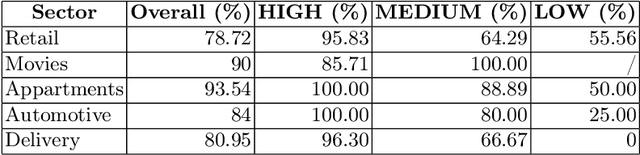
Enterprises often maintain multiple databases for storing critical business data in siloed systems, resulting in inefficiencies and challenges with data interoperability. A key to overcoming these challenges lies in integrating disparate data sources, enabling businesses to unlock the full potential of their data. Our work presents a novel approach for integrating multiple databases using knowledge graphs, focusing on the application of large language models as semantic agents for mapping and connecting structured data across systems by leveraging existing vocabularies. The proposed methodology introduces a semantic layer above tables in relational databases, utilizing a system comprising multiple LLM agents that map tables and columns to Schema.org terms. Our approach achieves a mapping accuracy of over 90% in multiple domains.
* The 1st GOBLIN Workshop on Knowledge Graph Technologies https://www.dbpedia.org/events/goblin25-workshop/
Building a Macedonian Recipe Dataset: Collection, Parsing, and Comparative Analysis
Oct 15, 2025Computational gastronomy increasingly relies on diverse, high-quality recipe datasets to capture regional culinary traditions. Although there are large-scale collections for major languages, Macedonian recipes remain under-represented in digital research. In this work, we present the first systematic effort to construct a Macedonian recipe dataset through web scraping and structured parsing. We address challenges in processing heterogeneous ingredient descriptions, including unit, quantity, and descriptor normalization. An exploratory analysis of ingredient frequency and co-occurrence patterns, using measures such as Pointwise Mutual Information and Lift score, highlights distinctive ingredient combinations that characterize Macedonian cuisine. The resulting dataset contributes a new resource for studying food culture in underrepresented languages and offers insights into the unique patterns of Macedonian culinary tradition.
Enhancing Knowledge Graph Construction Using Large Language Models
May 08, 2023



The growing trend of Large Language Models (LLM) development has attracted significant attention, with models for various applications emerging consistently. However, the combined application of Large Language Models with semantic technologies for reasoning and inference is still a challenging task. This paper analyzes how the current advances in foundational LLM, like ChatGPT, can be compared with the specialized pretrained models, like REBEL, for joint entity and relation extraction. To evaluate this approach, we conducted several experiments using sustainability-related text as our use case. We created pipelines for the automatic creation of Knowledge Graphs from raw texts, and our findings indicate that using advanced LLM models can improve the accuracy of the process of creating these graphs from unstructured text. Furthermore, we explored the potential of automatic ontology creation using foundation LLM models, which resulted in even more relevant and accurate knowledge graphs.
PharmKE: Knowledge Extraction Platform for Pharmaceutical Texts using Transfer Learning
Feb 25, 2021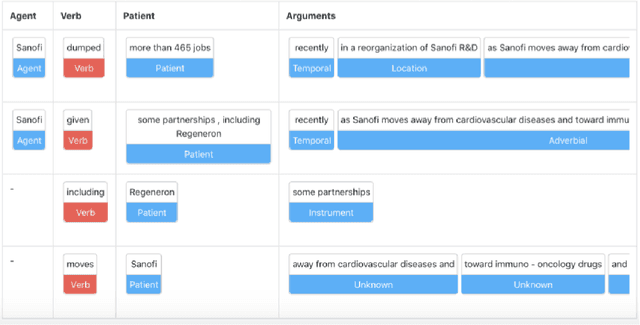
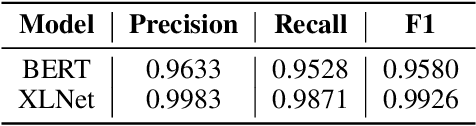
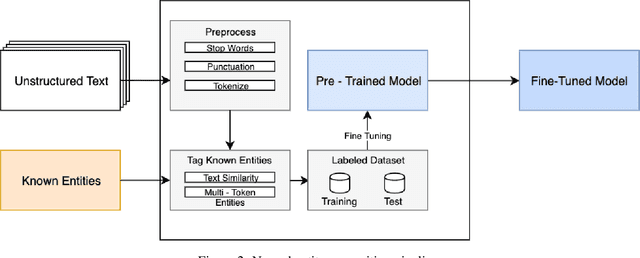
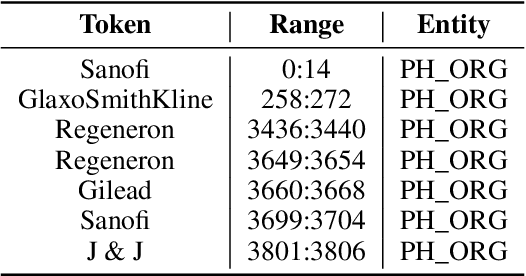
The challenge of recognizing named entities in a given text has been a very dynamic field in recent years. This is due to the advances in neural network architectures, increase of computing power and the availability of diverse labeled datasets, which deliver pre-trained, highly accurate models. These tasks are generally focused on tagging common entities, but domain-specific use-cases require tagging custom entities which are not part of the pre-trained models. This can be solved by either fine-tuning the pre-trained models, or by training custom models. The main challenge lies in obtaining reliable labeled training and test datasets, and manual labeling would be a highly tedious task. In this paper we present PharmKE, a text analysis platform focused on the pharmaceutical domain, which applies deep learning through several stages for thorough semantic analysis of pharmaceutical articles. It performs text classification using state-of-the-art transfer learning models, and thoroughly integrates the results obtained through a proposed methodology. The methodology is used to create accurately labeled training and test datasets, which are then used to train models for custom entity labeling tasks, centered on the pharmaceutical domain. The obtained results are compared to the fine-tuned BERT and BioBERT models trained on the same dataset. Additionally, the PharmKE platform integrates the results obtained from named entity recognition tasks to resolve co-references of entities and analyze the semantic relations in every sentence, thus setting up a baseline for additional text analysis tasks, such as question answering and fact extraction. The recognized entities are also used to expand the knowledge graph generated by DBpedia Spotlight for a given pharmaceutical text.