 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Fails, What Works? A Data-Driven Taxonomy of Real-World AI Risk Mitigation Strategies
Mar 04, 2026Large language models (LLMs) are increasingly embedded in high-stakes workflows, where failures propagate beyond isolated model errors into systemic breakdowns that can lead to legal exposure, reputational damage, and material financial losses. Building on this shift from model-centric risks to end-to-end system vulnerabilities, we analyze real-world AI incident reporting and mitigation actions to derive an empirically grounded taxonomy that links failure dynamics to actionable interventions. Using a unified corpus of 9,705 media-reported AI incident articles, we extract explicit mitigation actions from 6,893 texts via structured prompting and then systematically classify responses to extend MIT's AI Risk Mitigation Taxonomy. Our taxonomy introduces four new mitigation categories, including 1) Corrective and Restrictive Actions, 2) Legal/Regulatory and Enforcement Actions, 3) Financial, Economic, and Market Controls, and 4) Avoidance and Denial, capturing response patterns that are becoming increasingly prevalent as AI deployment and regulation evolve. Quantitatively, we label the mitigation dataset with 32 distinct labels, producing 23,994 label assignments; 9,629 of these reflect previously unseen mitigation patterns, yielding a 67% increase of the original subcategory coverage and substantially enhancing the taxonomy's applicability to emerging systemic failure modes. By structuring incident responses, the paper strengthens "diagnosis-to-prescription" guidance and advances continuous, taxonomy-aligned post-deployment monitoring to prevent cascading incidents and downstream impact.
AI Agent-Driven Framework for Automated Product Knowledge Graph Construction in E-Commerce
Nov 14, 2025The rapid expansion of e-commerce platforms generates vast amounts of unstructured product data, creating significant challenges for information retrieval, recommendation systems, and data analytics. Knowledge Graphs (KGs) offer a structured, interpretable format to organize such data, yet constructing product-specific KGs remains a complex and manual process. This paper introduces a fully automated, AI agent-driven framework for constructing product knowledge graphs directly from unstructured product descriptions. Leveraging Large Language Models (LLMs), our method operates in three stages using dedicated agents: ontology creation and expansion, ontology refinement, and knowledge graph population. This agent-based approach ensures semantic coherence, scalability, and high-quality output without relying on predefined schemas or handcrafted extraction rules. We evaluate the system on a real-world dataset of air conditioner product descriptions, demonstrating strong performance in both ontology generation and KG population. The framework achieves over 97\% property coverage and minimal redundancy, validating its effectiveness and practical applicability. Our work highlights the potential of LLMs to automate structured knowledge extraction in retail, providing a scalable path toward intelligent product data integration and utilization.
* Proceedings of the 1st GOBLIN Workshop on Knowledge Graph Technologies
A Multi-Agent System for Semantic Mapping of Relational Data to Knowledge Graphs
Nov 09, 2025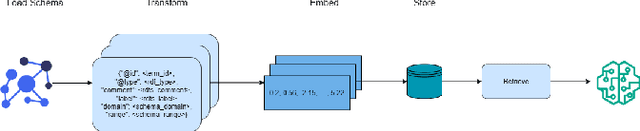
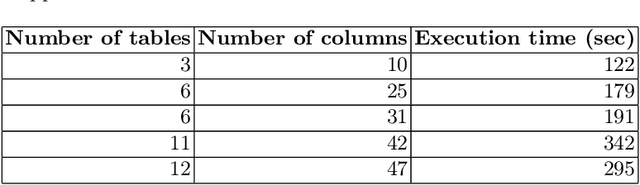
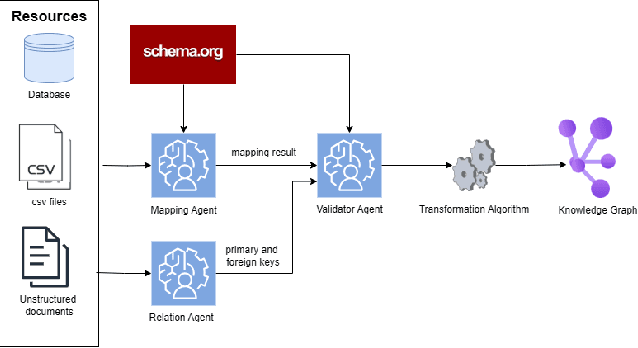
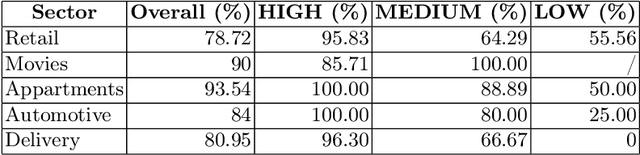
Enterprises often maintain multiple databases for storing critical business data in siloed systems, resulting in inefficiencies and challenges with data interoperability. A key to overcoming these challenges lies in integrating disparate data sources, enabling businesses to unlock the full potential of their data. Our work presents a novel approach for integrating multiple databases using knowledge graphs, focusing on the application of large language models as semantic agents for mapping and connecting structured data across systems by leveraging existing vocabularies. The proposed methodology introduces a semantic layer above tables in relational databases, utilizing a system comprising multiple LLM agents that map tables and columns to Schema.org terms. Our approach achieves a mapping accuracy of over 90% in multiple domains.
* The 1st GOBLIN Workshop on Knowledge Graph Technologies https://www.dbpedia.org/events/goblin25-workshop/
Building a Macedonian Recipe Dataset: Collection, Parsing, and Comparative Analysis
Oct 15, 2025Computational gastronomy increasingly relies on diverse, high-quality recipe datasets to capture regional culinary traditions. Although there are large-scale collections for major languages, Macedonian recipes remain under-represented in digital research. In this work, we present the first systematic effort to construct a Macedonian recipe dataset through web scraping and structured parsing. We address challenges in processing heterogeneous ingredient descriptions, including unit, quantity, and descriptor normalization. An exploratory analysis of ingredient frequency and co-occurrence patterns, using measures such as Pointwise Mutual Information and Lift score, highlights distinctive ingredient combinations that characterize Macedonian cuisine. The resulting dataset contributes a new resource for studying food culture in underrepresented languages and offers insights into the unique patterns of Macedonian culinary tradition.
Ontology-Based Structuring and Analysis of North Macedonian Public Procurement Contracts
May 14, 2025Public procurement plays a critical role in government operations, ensuring the efficient allocation of resources and fostering economic growth. However, traditional procurement data is often stored in rigid, tabular formats, limiting its analytical potential and hindering transparency. This research presents a methodological framework for transforming structured procurement data into a semantic knowledge graph, leveraging ontological modeling and automated data transformation techniques. By integrating RDF and SPARQL-based querying, the system enhances the accessibility and interpretability of procurement records, enabling complex semantic queries and advanced analytics. Furthermore, by incorporating machine learning-driven predictive modeling, the system extends beyond conventional data analysis, offering insights into procurement trends and risk assessment. This work contributes to the broader field of public procurement intelligence by improving data transparency, supporting evidence-based decision-making, and enabling in-depth analysis of procurement activities in North Macedonia.
Sentiment Analysis in Finance: From Transformers Back to eXplainable Lexicons (XLex)
Jun 06, 2023



Lexicon-based sentiment analysis (SA) in finance leverages specialized, manually annotated lexicons created by human experts to extract sentiment from financial texts. Although lexicon-based methods are simple to implement and fast to operate on textual data, they require considerable manual annotation efforts to create, maintain, and update the lexicons. These methods are also considered inferior to the deep learning-based approaches, such as transformer models, which have become dominant in various NLP tasks due to their remarkable performance. However, transformers require extensive data and computational resources for both training and testing. Additionally, they involve significant prediction times, making them unsuitable for real-time production environments or systems with limited processing capabilities. In this paper, we introduce a novel methodology named eXplainable Lexicons (XLex) that combines the advantages of both lexicon-based methods and transformer models. We propose an approach that utilizes transformers and SHapley Additive exPlanations (SHAP) for explainability to learn financial lexicons. Our study presents four main contributions. Firstly, we demonstrate that transformer-aided explainable lexicons can enhance the vocabulary coverage of the benchmark Loughran-McDonald (LM) lexicon, reducing the human involvement in annotating, maintaining, and updating the lexicons. Secondly, we show that the resulting lexicon outperforms the standard LM lexicon in SA of financial datasets. Thirdly, we illustrate that the lexicon-based approach is significantly more efficient in terms of model speed and size compared to transformers. Lastly, the XLex approach is inherently more interpretable than transformer models as lexicon models rely on predefined rules, allowing for better insights into the results of SA and making the XLex approach a viable tool for financial decision-making.
Enhancing Knowledge Graph Construction Using Large Language Models
May 08, 2023



The growing trend of Large Language Models (LLM) development has attracted significant attention, with models for various applications emerging consistently. However, the combined application of Large Language Models with semantic technologies for reasoning and inference is still a challenging task. This paper analyzes how the current advances in foundational LLM, like ChatGPT, can be compared with the specialized pretrained models, like REBEL, for joint entity and relation extraction. To evaluate this approach, we conducted several experiments using sustainability-related text as our use case. We created pipelines for the automatic creation of Knowledge Graphs from raw texts, and our findings indicate that using advanced LLM models can improve the accuracy of the process of creating these graphs from unstructured text. Furthermore, we explored the potential of automatic ontology creation using foundation LLM models, which resulted in even more relevant and accurate knowledge graphs.
Company classification using zero-shot learning
May 01, 2023



In recent years, natural language processing (NLP) has become increasingly important in a variety of business applications, including sentiment analysis, text classification, and named entity recognition. In this paper, we propose an approach for company classification using NLP and zero-shot learning. Our method utilizes pre-trained transformer models to extract features from company descriptions, and then applies zero-shot learning to classify companies into relevant categories without the need for specific training data for each category. We evaluate our approach on publicly available datasets of textual descriptions of companies, and demonstrate that it can streamline the process of company classification, thereby reducing the time and resources required in traditional approaches such as the Global Industry Classification Standard (GICS). The results show that this method has potential for automation of company classification, making it a promising avenue for future research in this area.
Survey of NLP in Pharmacology: Methodology, Tasks, Resources, Knowledge, and Tools
Aug 22, 2022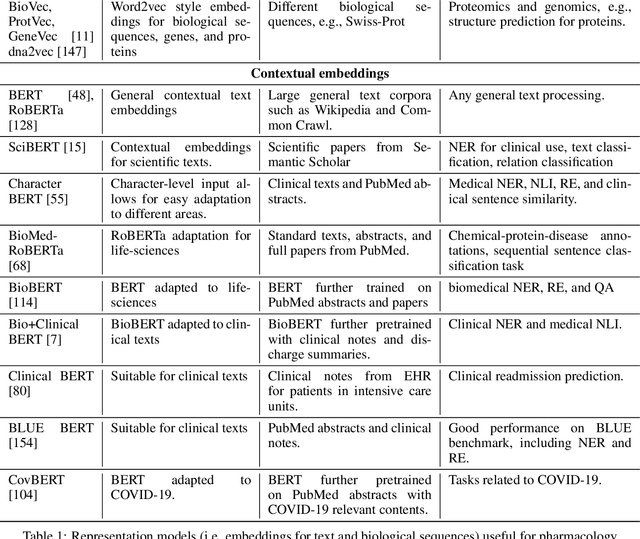
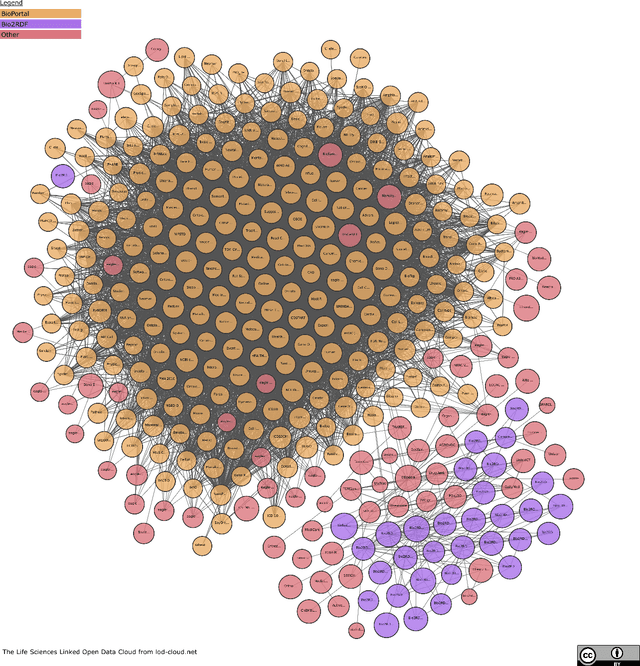

Natural language processing (NLP) is an area of artificial intelligence that applies information technologies to process the human language, understand it to a certain degree, and use it in various applications. This area has rapidly developed in the last few years and now employs modern variants of deep neural networks to extract relevant patterns from large text corpora. The main objective of this work is to survey the recent use of NLP in the field of pharmacology. As our work shows, NLP is a highly relevant information extraction and processing approach for pharmacology. It has been used extensively, from intelligent searches through thousands of medical documents to finding traces of adversarial drug interactions in social media. We split our coverage into five categories to survey modern NLP methodology, commonly addressed tasks, relevant textual data, knowledge bases, and useful programming libraries. We split each of the five categories into appropriate subcategories, describe their main properties and ideas, and summarize them in a tabular form. The resulting survey presents a comprehensive overview of the area, useful to practitioners and interested observers.
PharmKE: Knowledge Extraction Platform for Pharmaceutical Texts using Transfer Learning
Feb 25, 2021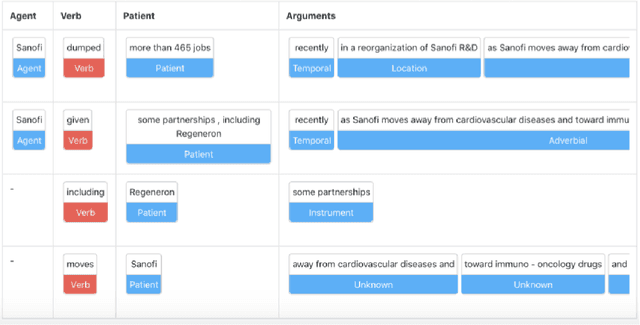
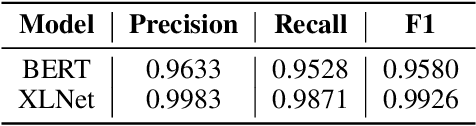
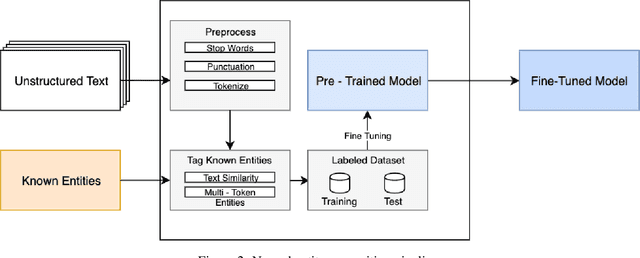
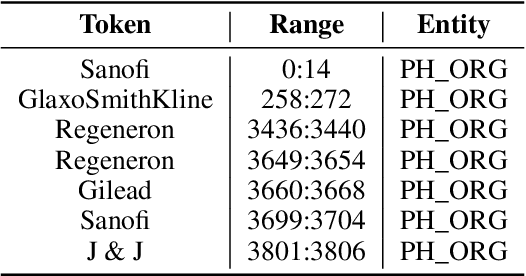
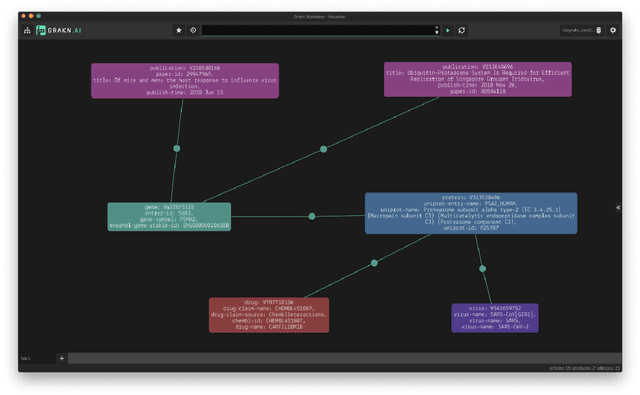
The challenge of recognizing named entities in a given text has been a very dynamic field in recent years. This is due to the advances in neural network architectures, increase of computing power and the availability of diverse labeled datasets, which deliver pre-trained, highly accurate models. These tasks are generally focused on tagging common entities, but domain-specific use-cases require tagging custom entities which are not part of the pre-trained models. This can be solved by either fine-tuning the pre-trained models, or by training custom models. The main challenge lies in obtaining reliable labeled training and test datasets, and manual labeling would be a highly tedious task. In this paper we present PharmKE, a text analysis platform focused on the pharmaceutical domain, which applies deep learning through several stages for thorough semantic analysis of pharmaceutical articles. It performs text classification using state-of-the-art transfer learning models, and thoroughly integrates the results obtained through a proposed methodology. The methodology is used to create accurately labeled training and test datasets, which are then used to train models for custom entity labeling tasks, centered on the pharmaceutical domain. The obtained results are compared to the fine-tuned BERT and BioBERT models trained on the same dataset. Additionally, the PharmKE platform integrates the results obtained from named entity recognition tasks to resolve co-references of entities and analyze the semantic relations in every sentence, thus setting up a baseline for additional text analysis tasks, such as question answering and fact extraction. The recognized entities are also used to expand the knowledge graph generated by DBpedia Spotlight for a given pharmaceutical text.