Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlovene SuperGLUE Benchmark: Translation and Evaluation
Paper and Code
Feb 10, 2022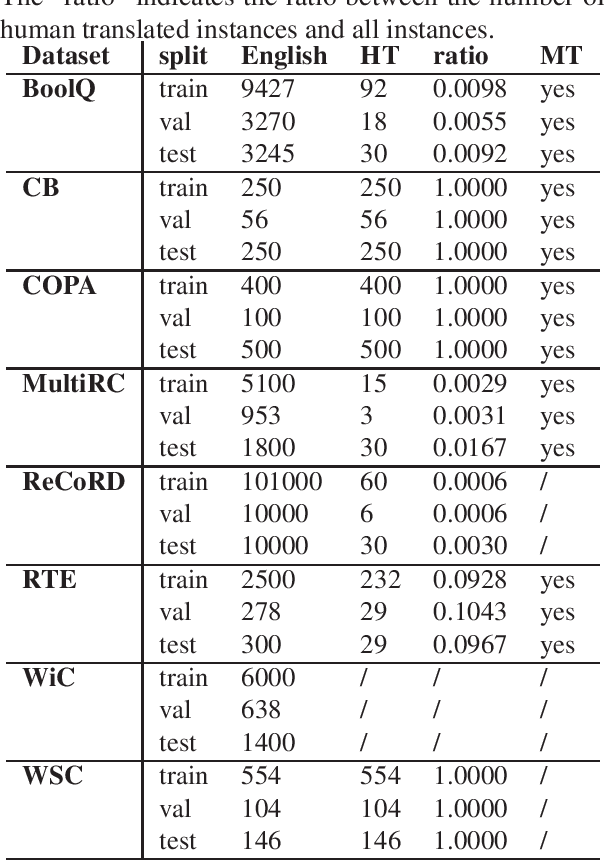
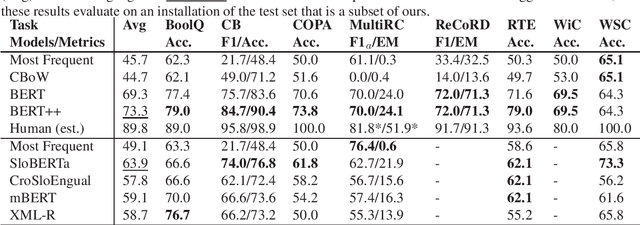


We present a Slovene combined machine-human translated SuperGLUE benchmark. We describe the translation process and problems arising due to differences in morphology and grammar. We evaluate the translated datasets in several modes: monolingual, cross-lingual, and multilingual, taking into account differences between machine and human translated training sets. The results show that the monolingual Slovene SloBERTa model is superior to massively multilingual and trilingual BERT models, but these also show a good cross-lingual performance on certain tasks. The performance of Slovene models still lags behind the best English models.
* arXiv admin note: text overlap with arXiv:2107.10614
View paper on