 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Approach to Abstractive Summarization
Paper and Code
Dec 08, 2020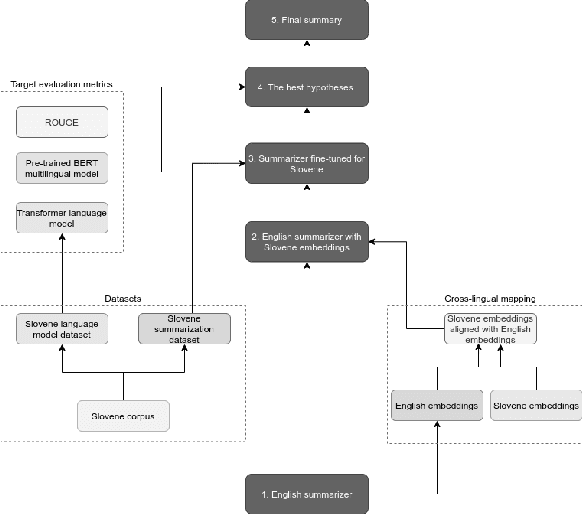

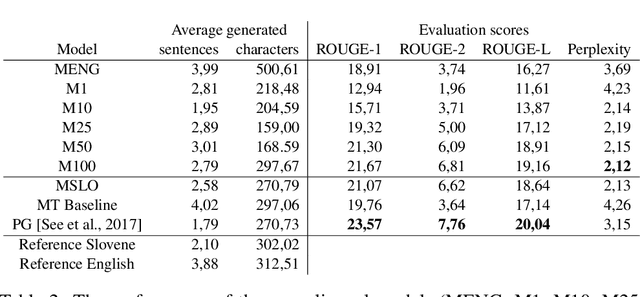
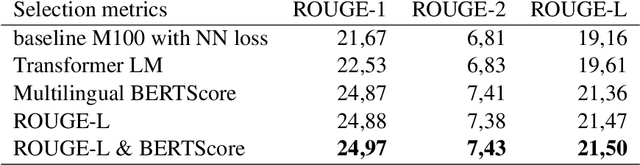
Automatic text summarization extracts important information from texts and presents the information in the form of a summary. Abstractive summarization approaches progressed significantly by switching to deep neural networks, but results are not yet satisfactory, especially for languages where large training sets do not exist. In several natural language processing tasks, cross-lingual model transfers are successfully applied in low-resource languages. For summarization such cross-lingual model transfer was so far not attempted due to a non-reusable decoder side of neural models. In our work, we used a pretrained English summarization model based on deep neural networks and sequence-to-sequence architecture to summarize Slovene news articles. We solved the problem of inadequate decoder by using an additional language model for target language evaluation. We developed several models with different proportions of target language data for fine-tuning. The results were assessed with automatic evaluation measures and with small-scale human evaluation. The results show that summaries of cross-lingual models fine-tuned with relatively small amount of target language data are useful and of similar quality to an abstractive summarizer trained with much more data in the target language.