 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024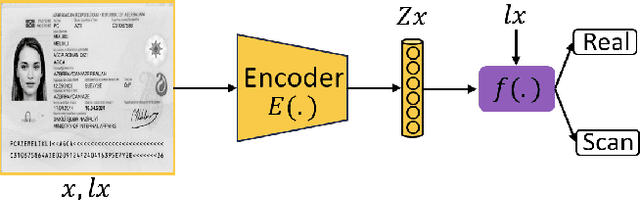
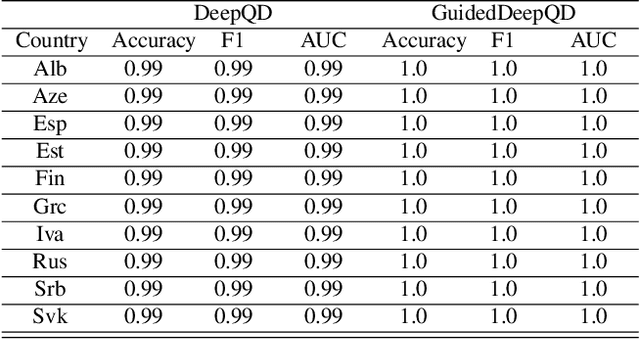
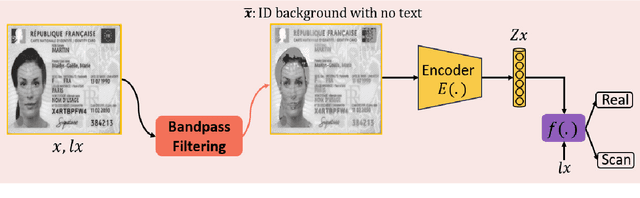
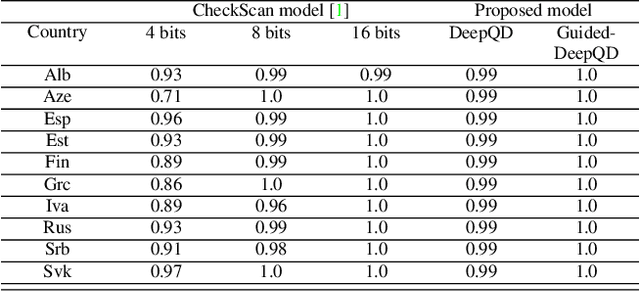
The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
Evaluation of Neural Network Classification Systems on Document Stream
Jul 15, 2020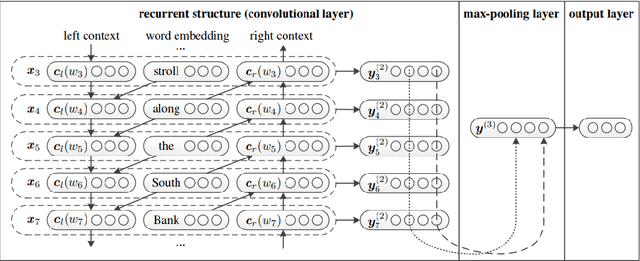
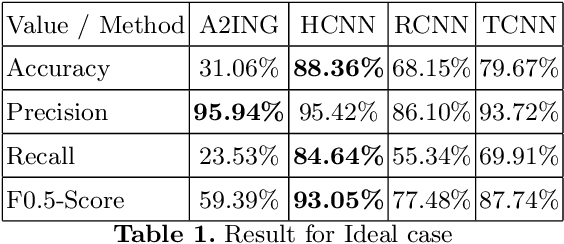
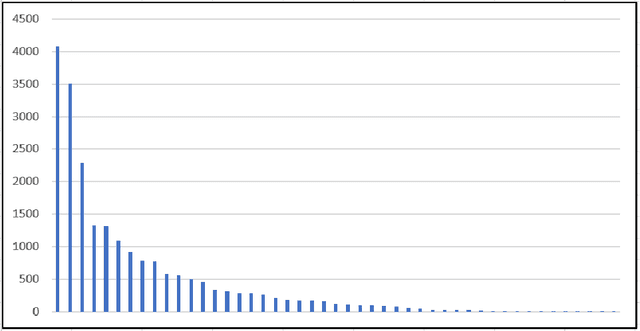
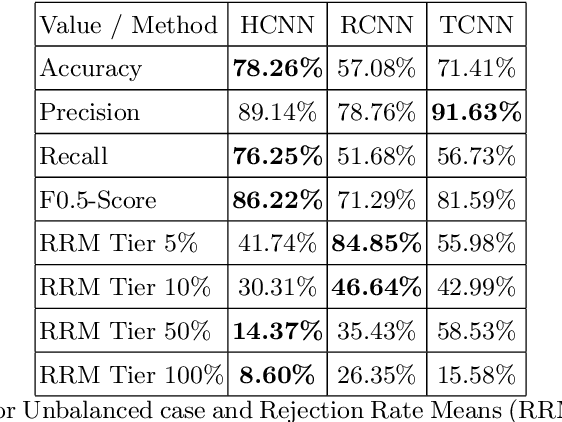
One major drawback of state of the art Neural Networks (NN)-based approaches for document classification purposes is the large number of training samples required to obtain an efficient classification. The minimum required number is around one thousand annotated documents for each class. In many cases it is very difficult, if not impossible, to gather this number of samples in real industrial processes. In this paper, we analyse the efficiency of NN-based document classification systems in a sub-optimal training case, based on the situation of a company document stream. We evaluated three different approaches, one based on image content and two on textual content. The evaluation was divided into four parts: a reference case, to assess the performance of the system in the lab; two cases that each simulate a specific difficulty linked to document stream processing; and a realistic case that combined all of these difficulties. The realistic case highlighted the fact that there is a significant drop in the efficiency of NN-Based document classification systems. Although they remain efficient for well represented classes (with an over-fitting of the system for those classes), it is impossible for them to handle appropriately less well represented classes. NN-Based document classification systems need to be adapted to resolve these two problems before they can be considered for use in a company document stream.