 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Information Extraction from Transactional Documents
Dec 10, 2025This paper presents a neurosymbolic framework for information extraction from documents, evaluated on transactional documents. We introduce a schema-based approach that integrates symbolic validation methods to enable more effective zero-shot output and knowledge distillation. The methodology uses language models to generate candidate extractions, which are then filtered through syntactic-, task-, and domain-level validation to ensure adherence to domain-specific arithmetic constraints. Our contributions include a comprehensive schema for transactional documents, relabeled datasets, and an approach for generating high-quality labels for knowledge distillation. Experimental results demonstrate significant improvements in $F_1$-scores and accuracy, highlighting the effectiveness of neurosymbolic validation in transactional document processing.
* 20 pages, 2 figures, accepted to IJDAR (ICDAR 2025)
QUEST: Quality-aware Semi-supervised Table Extraction for Business Documents
Jun 17, 2025Automating table extraction (TE) from business documents is critical for industrial workflows but remains challenging due to sparse annotations and error-prone multi-stage pipelines. While semi-supervised learning (SSL) can leverage unlabeled data, existing methods rely on confidence scores that poorly reflect extraction quality. We propose QUEST, a Quality-aware Semi-supervised Table extraction framework designed for business documents. QUEST introduces a novel quality assessment model that evaluates structural and contextual features of extracted tables, trained to predict F1 scores instead of relying on confidence metrics. This quality-aware approach guides pseudo-label selection during iterative SSL training, while diversity measures (DPP, Vendi score, IntDiv) mitigate confirmation bias. Experiments on a proprietary business dataset (1000 annotated + 10000 unannotated documents) show QUEST improves F1 from 64% to 74% and reduces empty predictions by 45% (from 12% to 6.5%). On the DocILE benchmark (600 annotated + 20000 unannotated documents), QUEST achieves a 50% F1 score (up from 42%) and reduces empty predictions by 19% (from 27% to 22%). The framework's interpretable quality assessments and robustness to annotation scarcity make it particularly suited for business documents, where structural consistency and data completeness are paramount.
RAPTOR: Refined Approach for Product Table Object Recognition
Feb 24, 2025Extracting tables from documents is a critical task across various industries, especially on business documents like invoices and reports. Existing systems based on DEtection TRansformer (DETR) such as TAble TRansformer (TATR), offer solutions for Table Detection (TD) and Table Structure Recognition (TSR) but face challenges with diverse table formats and common errors like incorrect area detection and overlapping columns. This research introduces RAPTOR, a modular post-processing system designed to enhance state-of-the-art models for improved table extraction, particularly for product tables. RAPTOR addresses recurrent TD and TSR issues, improving both precision and structural predictions. For TD, we use DETR (trained on ICDAR 2019) and TATR (trained on PubTables-1M and FinTabNet), while TSR only relies on TATR. A Genetic Algorithm is incorporated to optimize RAPTOR's module parameters, using a private dataset of product tables to align with industrial needs. We evaluate our method on two private datasets of product tables, the public DOCILE dataset (which contains tables similar to our target product tables), and the ICDAR 2013 and ICDAR 2019 datasets. The results demonstrate that while our approach excels at product tables, it also maintains reasonable performance across diverse table formats. An ablation study further validates the contribution of each module in our system.
KhmerST: A Low-Resource Khmer Scene Text Detection and Recognition Benchmark
Oct 23, 2024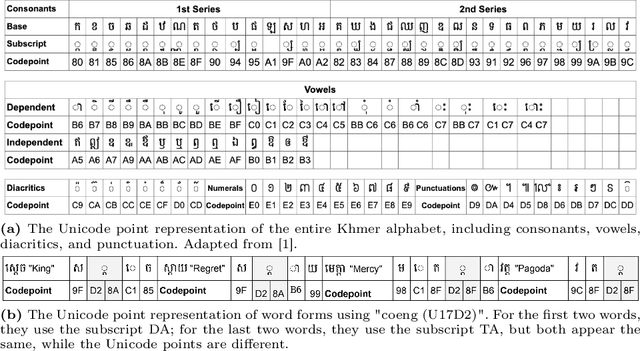
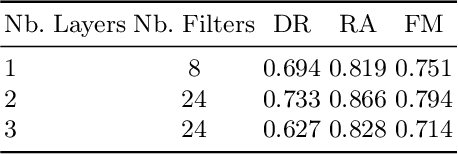

Developing effective scene text detection and recognition models hinges on extensive training data, which can be both laborious and costly to obtain, especially for low-resourced languages. Conventional methods tailored for Latin characters often falter with non-Latin scripts due to challenges like character stacking, diacritics, and variable character widths without clear word boundaries. In this paper, we introduce the first Khmer scene-text dataset, featuring 1,544 expert-annotated images, including 997 indoor and 547 outdoor scenes. This diverse dataset includes flat text, raised text, poorly illuminated text, distant and partially obscured text. Annotations provide line-level text and polygonal bounding box coordinates for each scene. The benchmark includes baseline models for scene-text detection and recognition tasks, providing a robust starting point for future research endeavors. The KhmerST dataset is publicly accessible at https://gitlab.com/vannkinhnom123/khmerst.
Confidence-Aware Document OCR Error Detection
Sep 06, 2024Optical Character Recognition (OCR) continues to face accuracy challenges that impact subsequent applications. To address these errors, we explore the utility of OCR confidence scores for enhancing post-OCR error detection. Our study involves analyzing the correlation between confidence scores and error rates across different OCR systems. We develop ConfBERT, a BERT-based model that incorporates OCR confidence scores into token embeddings and offers an optional pre-training phase for noise adjustment. Our experimental results demonstrate that integrating OCR confidence scores can enhance error detection capabilities. This work underscores the importance of OCR confidence scores in improving detection accuracy and reveals substantial disparities in performance between commercial and open-source OCR technologies.
Lazy-k: Decoding for Constrained Token Classification
Dec 06, 2023We explore the possibility of improving probabilistic models in structured prediction. Specifically, we combine the models with constrained decoding approaches in the context of token classification for information extraction. The decoding methods search for constraint-satisfying label-assignments while maximizing the total probability. To do this, we evaluate several existing approaches, as well as propose a novel decoding method called Lazy-$k$. Our findings demonstrate that constrained decoding approaches can significantly improve the models' performances, especially when using smaller models. The Lazy-$k$ approach allows for more flexibility between decoding time and accuracy. The code for using Lazy-$k$ decoding can be found here: https://github.com/ArthurDevNL/lazyk.
Estimating Post-OCR Denoising Complexity on Numerical Texts
Jul 03, 2023Post-OCR processing has significantly improved over the past few years. However, these have been primarily beneficial for texts consisting of natural, alphabetical words, as opposed to documents of numerical nature such as invoices, payslips, medical certificates, etc. To evaluate the OCR post-processing difficulty of these datasets, we propose a method to estimate the denoising complexity of a text and evaluate it on several datasets of varying nature, and show that texts of numerical nature have a significant disadvantage. We evaluate the estimated complexity ranking with respect to the error rates of modern-day denoising approaches to show the validity of our estimator.
CHIC: Corporate Document for Visual question Answering
May 01, 2023The massive use of digital documents due to the substantial trend of paperless initiatives confronted some companies to find ways to process thousands of documents per day automatically. To achieve this, they use automatic information retrieval (IR) allowing them to extract useful information from large datasets quickly. In order to have effective IR methods, it is first necessary to have an adequate dataset. Although companies have enough data to take into account their needs, there is also a need for a public database to compare contributions between state-of-the-art methods. Public data on the document exists as DocVQA[2] and XFUND [10], but these do not fully satisfy the needs of companies. XFUND contains only form documents while the company uses several types of documents (i.e. structured documents like forms but also semi-structured as invoices, and unstructured as emails). Compared to XFUND, DocVQA has several types of documents but only 4.5% of them are corporate documents (i.e. invoice, purchase order, etc). All of this 4.5% of documents do not meet the diversity of documents required by the company. We propose CHIC a visual question-answering public dataset. This dataset contains different types of corporate documents and the information extracted from these documents meet the right expectations of companies.
Evaluation of Neural Network Classification Systems on Document Stream
Jul 15, 2020
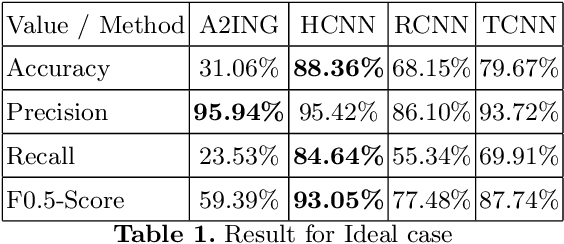
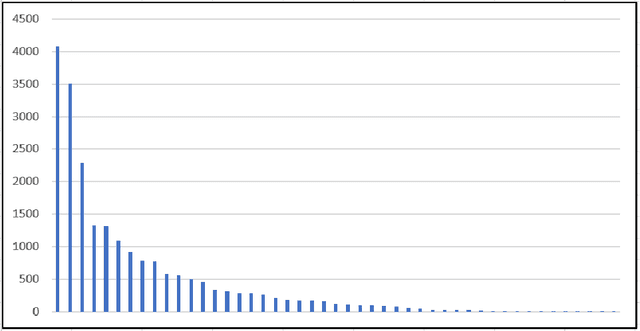
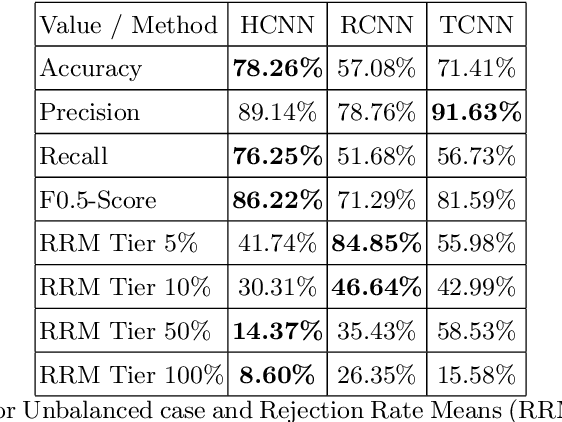
One major drawback of state of the art Neural Networks (NN)-based approaches for document classification purposes is the large number of training samples required to obtain an efficient classification. The minimum required number is around one thousand annotated documents for each class. In many cases it is very difficult, if not impossible, to gather this number of samples in real industrial processes. In this paper, we analyse the efficiency of NN-based document classification systems in a sub-optimal training case, based on the situation of a company document stream. We evaluated three different approaches, one based on image content and two on textual content. The evaluation was divided into four parts: a reference case, to assess the performance of the system in the lab; two cases that each simulate a specific difficulty linked to document stream processing; and a realistic case that combined all of these difficulties. The realistic case highlighted the fact that there is a significant drop in the efficiency of NN-Based document classification systems. Although they remain efficient for well represented classes (with an over-fitting of the system for those classes), it is impossible for them to handle appropriately less well represented classes. NN-Based document classification systems need to be adapted to resolve these two problems before they can be considered for use in a company document stream.
Performance Evaluation of Deep Generative Models for Generating Hand-Written Character Images
Feb 26, 2020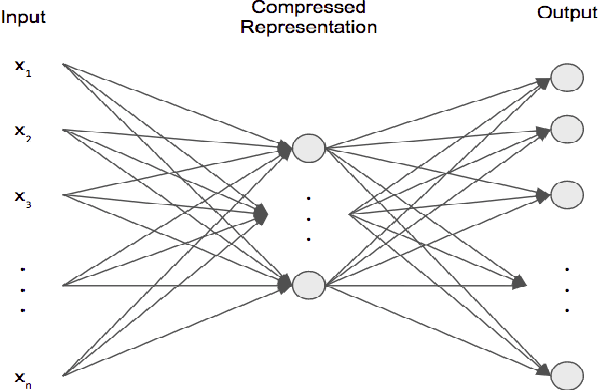
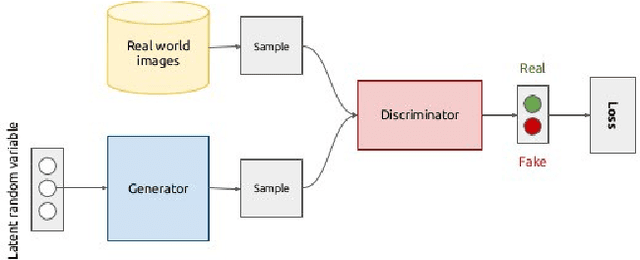
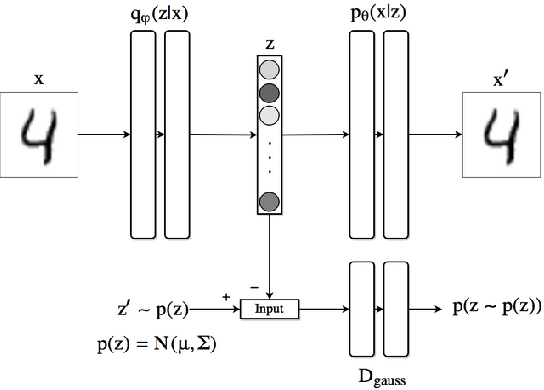
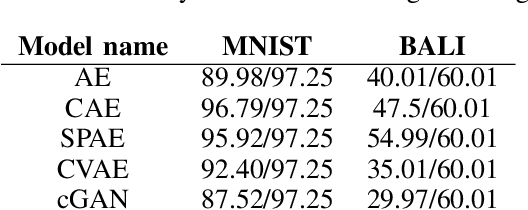
There have been many work in the literature on generation of various kinds of images such as Hand-Written characters (MNIST dataset), scene images (CIFAR-10 dataset), various objects images (ImageNet dataset), road signboard images (SVHN dataset) etc. Unfortunately, there have been very limited amount of work done in the domain of document image processing. Automatic image generation can lead to the enormous increase of labeled datasets with the help of only limited amount of labeled data. Various kinds of Deep generative models can be primarily divided into two categories. First category is auto-encoder (AE) and the second one is Generative Adversarial Networks (GANs). In this paper, we have evaluated various kinds of AE as well as GANs and have compared their performances on hand-written digits dataset (MNIST) and also on historical hand-written character dataset of Indonesian BALI language. Moreover, these generated characters are recognized by using character recognition tool for calculating the statistical performance of these generated characters with respect to original character images.