 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Informed and Data Driven Simulation of Underwater Images via Residual Learning
Feb 07, 2024In general, underwater images suffer from color distortion and low contrast, because light is attenuated and backscattered as it propagates through water (differently depending on wavelength and on the properties of the water body). An existing simple degradation model (similar to atmospheric image "hazing" effects), though helpful, is not sufficient to properly represent the underwater image degradation because there are unaccounted for and non-measurable factors e.g. scattering of light due to turbidity of water, reflective characteristics of turbid medium etc. We propose a deep learning-based architecture to automatically simulate the underwater effects where only a dehazing-like image formation equation is known to the network, and the additional degradation due to the other unknown factors if inferred in a data-driven way. We only use RGB images (because in real-time scenario depth image is not available) to estimate the depth image. For testing, we have proposed (due to the lack of real underwater image datasets) a complex image formation model/equation to manually generate images that resemble real underwater images (used as ground truth). However, only the classical image formation equation (the one used for image dehazing) is informed to the network. This mimics the fact that in a real scenario, the physics are never completely known and only simplified models are known. Thanks to the ground truth, generated by a complex image formation equation, we could successfully perform a qualitative and quantitative evaluation of proposed technique, compared to other purely data driven approaches
Exploring Multi-Tasking Learning in Document Attribute Classification
Aug 30, 2021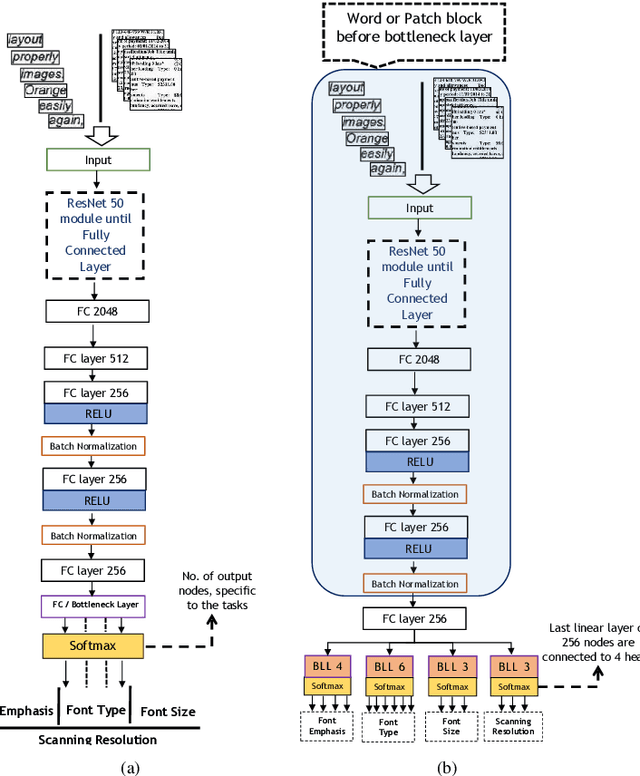
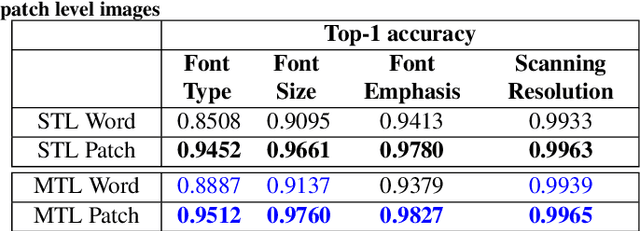
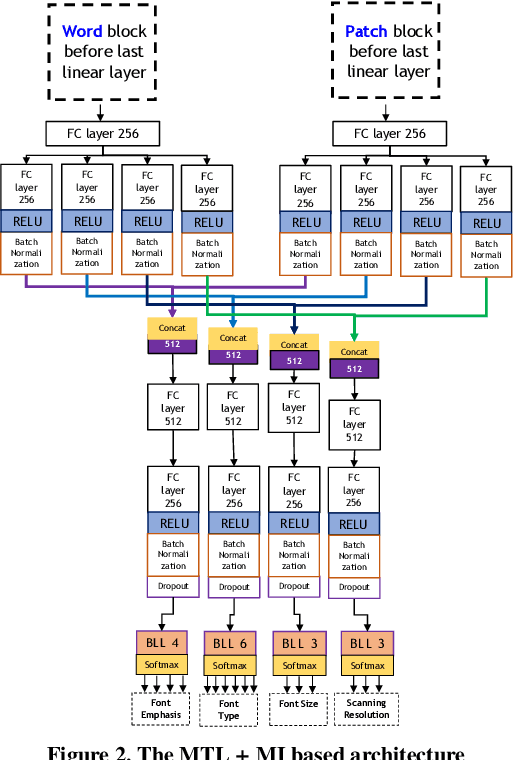

In this work, we adhere to explore a Multi-Tasking learning (MTL) based network to perform document attribute classification such as the font type, font size, font emphasis and scanning resolution classification of a document image. To accomplish these tasks, we operate on either segmented word level or on uniformed size patches randomly cropped out of the document. Furthermore, a hybrid convolution neural network (CNN) architecture "MTL+MI", which is based on the combination of MTL and Multi-Instance (MI) of patch and word is used to accomplish joint learning for the classification of the same document attributes. The contribution of this paper are three fold: firstly, based on segmented word images and patches, we present a MTL based network for the classification of a full document image. Secondly, we propose a MTL and MI (using segmented words and patches) based combined CNN architecture ("MTL+MI") for the classification of same document attributes. Thirdly, based on the multi-tasking classifications of the words and/or patches, we propose an intelligent voting system which is based on the posterior probabilities of each words and/or patches to perform the classification of document's attributes of complete document image.
Performance Evaluation of Deep Generative Models for Generating Hand-Written Character Images
Feb 26, 2020
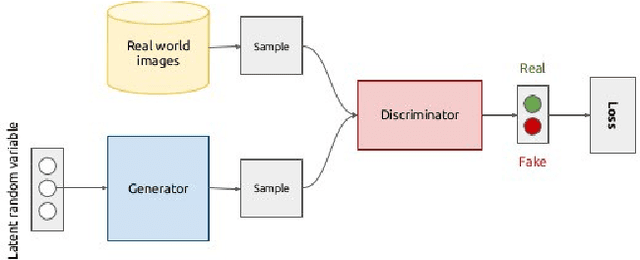
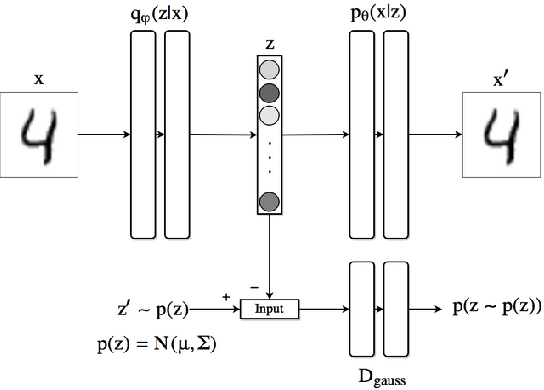
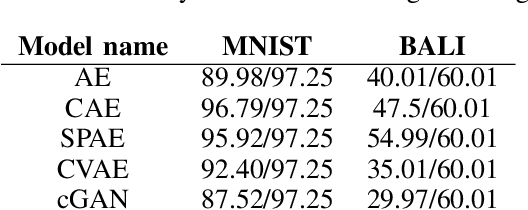
There have been many work in the literature on generation of various kinds of images such as Hand-Written characters (MNIST dataset), scene images (CIFAR-10 dataset), various objects images (ImageNet dataset), road signboard images (SVHN dataset) etc. Unfortunately, there have been very limited amount of work done in the domain of document image processing. Automatic image generation can lead to the enormous increase of labeled datasets with the help of only limited amount of labeled data. Various kinds of Deep generative models can be primarily divided into two categories. First category is auto-encoder (AE) and the second one is Generative Adversarial Networks (GANs). In this paper, we have evaluated various kinds of AE as well as GANs and have compared their performances on hand-written digits dataset (MNIST) and also on historical hand-written character dataset of Indonesian BALI language. Moreover, these generated characters are recognized by using character recognition tool for calculating the statistical performance of these generated characters with respect to original character images.