 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast matrix multiplication for binary and ternary CNNs on ARM CPU
Paper and Code
May 18, 2022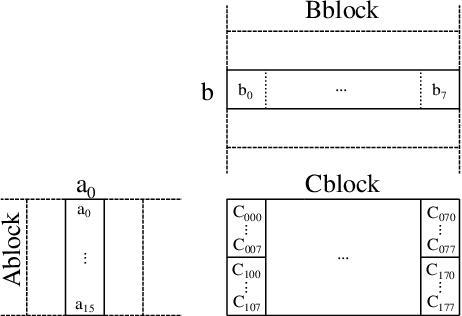
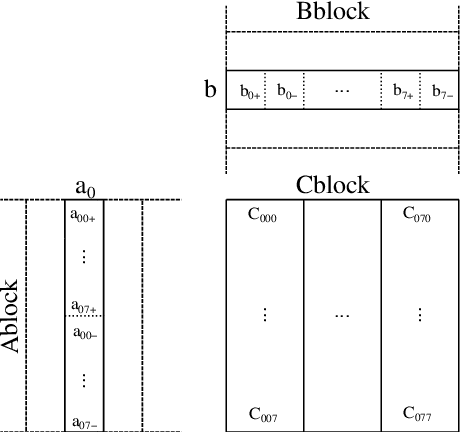
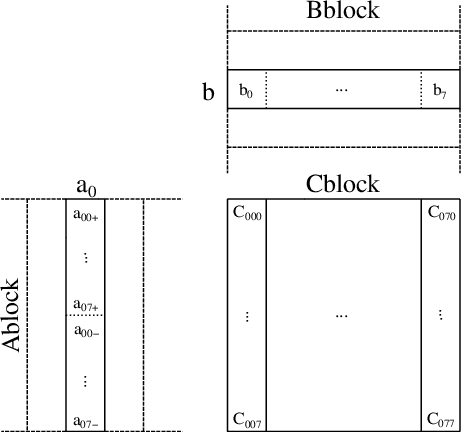

Low-bit quantized neural networks are of great interest in practical applications because they significantly reduce the consumption of both memory and computational resources. Binary neural networks are memory and computationally efficient as they require only one bit per weight and activation and can be computed using Boolean logic and bit count operations. QNNs with ternary weights and activations and binary weights and ternary activations aim to improve recognition quality compared to BNNs while preserving low bit-width. However, their efficient implementation is usually considered on ASICs and FPGAs, limiting their applicability in real-life tasks. At the same time, one of the areas where efficient recognition is most in demand is recognition on mobile devices using their CPUs. However, there are no known fast implementations of TBNs and TNN, only the daBNN library for BNNs inference. In this paper, we propose novel fast algorithms of ternary, ternary-binary, and binary matrix multiplication for mobile devices with ARM architecture. In our algorithms, ternary weights are represented using 2-bit encoding and binary - using one bit. It allows us to replace matrix multiplication with Boolean logic operations that can be computed on 128-bits simultaneously, using ARM NEON SIMD extension. The matrix multiplication results are accumulated in 16-bit integer registers. We also use special reordering of values in left and right matrices. All that allows us to efficiently compute a matrix product while minimizing the number of loads and stores compared to the algorithm from daBNN. Our algorithms can be used to implement inference of convolutional and fully connected layers of TNNs, TBNs, and BNNs. We evaluate them experimentally on ARM Cortex-A73 CPU and compare their inference speed to efficient implementations of full-precision, 8-bit, and 4-bit quantized matrix multiplications.