 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Analysis and Comparison of Alphabets in Historical Handwritten Ciphers
Oct 29, 2024

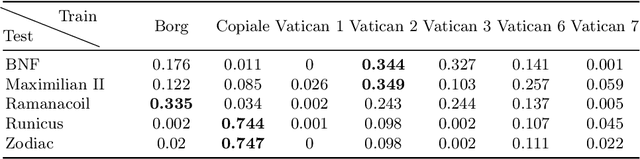

Historical ciphered manuscripts are documents that were typically used in sensitive communications within military and diplomatic contexts or among members of secret societies. These secret messages were concealed by inventing a method of writing employing symbols from diverse sources such as digits, alchemy signs and Latin or Greek characters. When studying a new, unseen cipher, the automatic search and grouping of ciphers with a similar alphabet can aid the scholar in its transcription and cryptanalysis because it indicates a probability that the underlying cipher is similar. In this study, we address this need by proposing the CSI metric, a novel way of comparing pairs of ciphered documents. We assess their effectiveness in an unsupervised clustering scenario utilising visual features, including SIFT, pre-trained learnt embeddings, and OCR descriptors.
Date Estimation in the Wild of Scanned Historical Photos: An Image Retrieval Approach
Jun 10, 2021
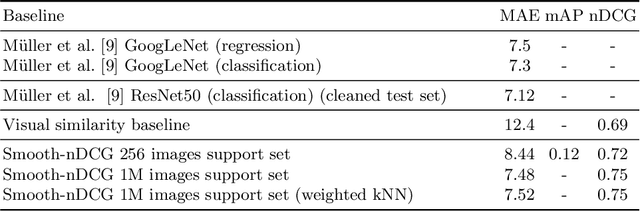

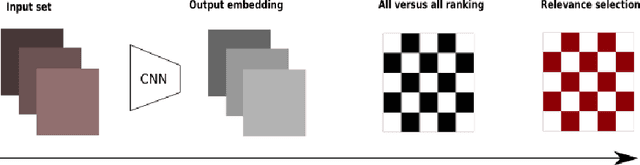
This paper presents a novel method for date estimation of historical photographs from archival sources. The main contribution is to formulate the date estimation as a retrieval task, where given a query, the retrieved images are ranked in terms of the estimated date similarity. The closer are their embedded representations the closer are their dates. Contrary to the traditional models that design a neural network that learns a classifier or a regressor, we propose a learning objective based on the nDCG ranking metric. We have experimentally evaluated the performance of the method in two different tasks: date estimation and date-sensitive image retrieval, using the DEW public database, overcoming the baseline methods.
Learning to Rank Words: Optimizing Ranking Metrics for Word Spotting
Jun 09, 2021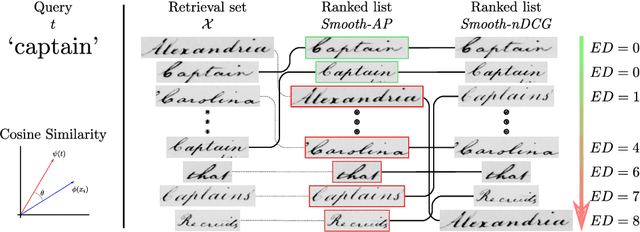
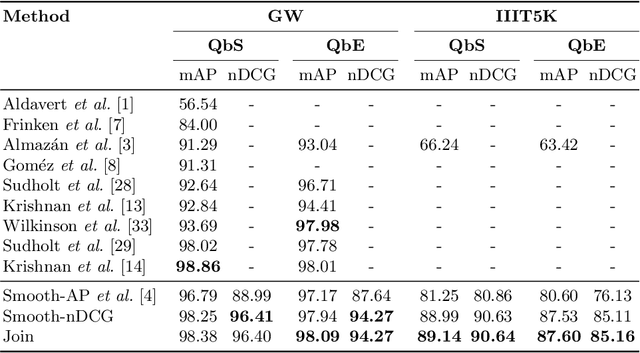
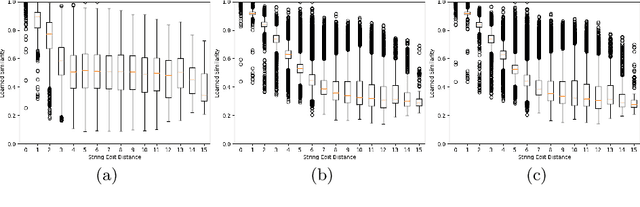
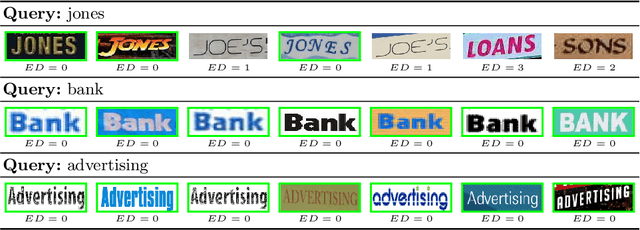
In this paper, we explore and evaluate the use of ranking-based objective functions for learning simultaneously a word string and a word image encoder. We consider retrieval frameworks in which the user expects a retrieval list ranked according to a defined relevance score. In the context of a word spotting problem, the relevance score has been set according to the string edit distance from the query string. We experimentally demonstrate the competitive performance of the proposed model on query-by-string word spotting for both, handwritten and real scene word images. We also provide the results for query-by-example word spotting, although it is not the main focus of this work.