 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSynth: A Layout Guided Approach for Controllable Document Image Synthesis
Paper and Code
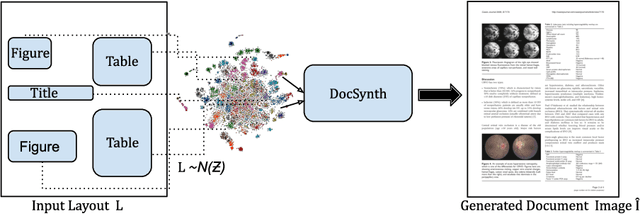

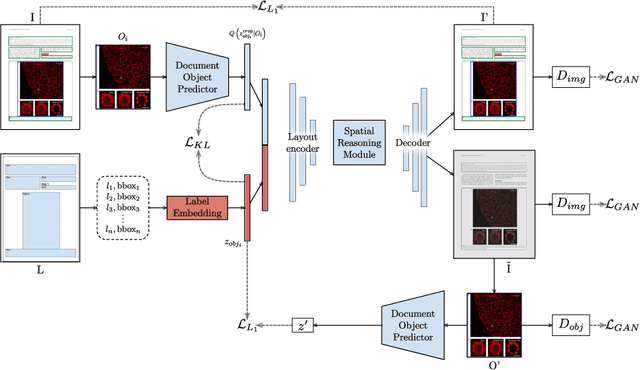

Despite significant progress on current state-of-the-art image generation models, synthesis of document images containing multiple and complex object layouts is a challenging task. This paper presents a novel approach, called DocSynth, to automatically synthesize document images based on a given layout. In this work, given a spatial layout (bounding boxes with object categories) as a reference by the user, our proposed DocSynth model learns to generate a set of realistic document images consistent with the defined layout. Also, this framework has been adapted to this work as a superior baseline model for creating synthetic document image datasets for augmenting real data during training for document layout analysis tasks. Different sets of learning objectives have been also used to improve the model performance. Quantitatively, we also compare the generated results of our model with real data using standard evaluation metrics. The results highlight that our model can successfully generate realistic and diverse document images with multiple objects. We also present a comprehensive qualitative analysis summary of the different scopes of synthetic image generation tasks. Lastly, to our knowledge this is the first work of its kind.