 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreyNet: A Neural Model for Text Localization, Transcription and Named Entity Recognition in Full Pages
Dec 20, 2019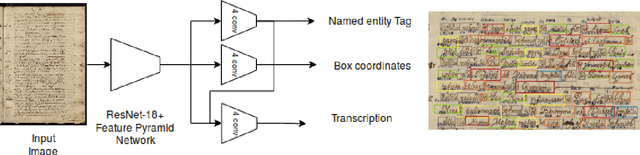
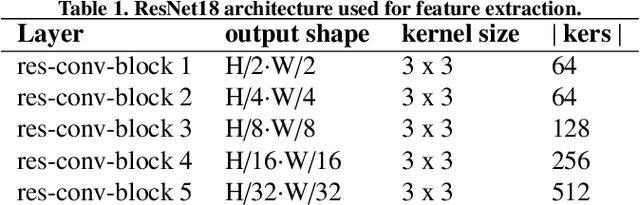
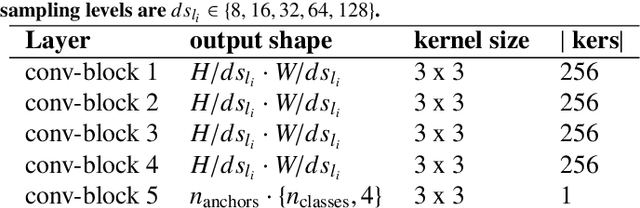
In the last years, the consolidation of deep neural network architectures for information extraction in document images has brought big improvements in the performance of each of the tasks involved in this process, consisting of text localization, transcription, and named entity recognition. However, this process is traditionally performed with separate methods for each task. In this work we propose an end-to-end model that jointly performs handwritten text detection, transcription, and named entity recognition at page level, capable of benefiting from shared features for these tasks. We exhaustively evaluate our approach on different datasets, discussing its advantages and limitations compared to sequential approaches.
Joint Recognition of Handwritten Text and Named Entities with a Neural End-to-end Model
Mar 22, 2018



When extracting information from handwritten documents, text transcription and named entity recognition are usually faced as separate subsequent tasks. This has the disadvantage that errors in the first module affect heavily the performance of the second module. In this work we propose to do both tasks jointly, using a single neural network with a common architecture used for plain text recognition. Experimentally, the work has been tested on a collection of historical marriage records. Results of experiments are presented to show the effect on the performance for different configurations: different ways of encoding the information, doing or not transfer learning and processing at text line or multi-line region level. The results are comparable to state of the art reported in the ICDAR 2017 Information Extraction competition, even though the proposed technique does not use any dictionaries, language modeling or post processing.