 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Few Shot Multi-Representation Approach for N-gram Spotting in Historical Manuscripts
Paper and Code
Sep 21, 2022
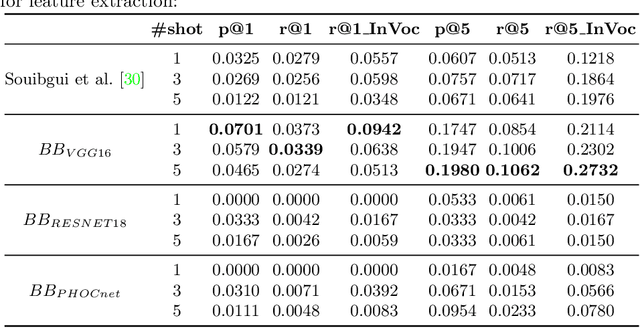

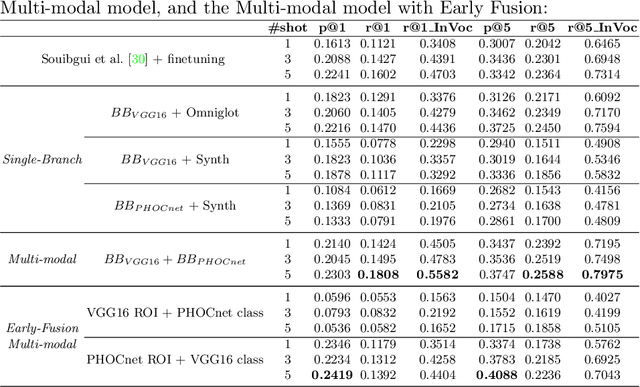
Despite recent advances in automatic text recognition, the performance remains moderate when it comes to historical manuscripts. This is mainly because of the scarcity of available labelled data to train the data-hungry Handwritten Text Recognition (HTR) models. The Keyword Spotting System (KWS) provides a valid alternative to HTR due to the reduction in error rate, but it is usually limited to a closed reference vocabulary. In this paper, we propose a few-shot learning paradigm for spotting sequences of a few characters (N-gram) that requires a small amount of labelled training data. We exhibit that recognition of important n-grams could reduce the system's dependency on vocabulary. In this case, an out-of-vocabulary (OOV) word in an input handwritten line image could be a sequence of n-grams that belong to the lexicon. An extensive experimental evaluation of our proposed multi-representation approach was carried out on a subset of Bentham's historical manuscript collections to obtain some really promising results in this direction.