 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWriting Order Recovery in Complex and Long Static Handwriting
Jun 05, 2024The order in which the trajectory is executed is a powerful source of information for recognizers. However, there is still no general approach for recovering the trajectory of complex and long handwriting from static images. Complex specimens can result in multiple pen-downs and in a high number of trajectory crossings yielding agglomerations of pixels (also known as clusters). While the scientific literature describes a wide range of approaches for recovering the writing order in handwriting, these approaches nevertheless lack a common evaluation metric. In this paper, we introduce a new system to estimate the order recovery of thinned static trajectories, which allows to effectively resolve the clusters and select the order of the executed pen-downs. We evaluate how knowing the starting points of the pen-downs affects the quality of the recovered writing. Once the stability and sensitivity of the system is analyzed, we describe a series of experiments with three publicly available databases, showing competitive results in all cases. We expect the proposed system, whose code is made publicly available to the research community, to reduce potential confusion when the order of complex trajectories are recovered, and this will in turn make the trajectories recovered to be viable for further applications, such as velocity estimation.
SM-DTW: Stability Modulated Dynamic Time Warping for signature verification
May 20, 2024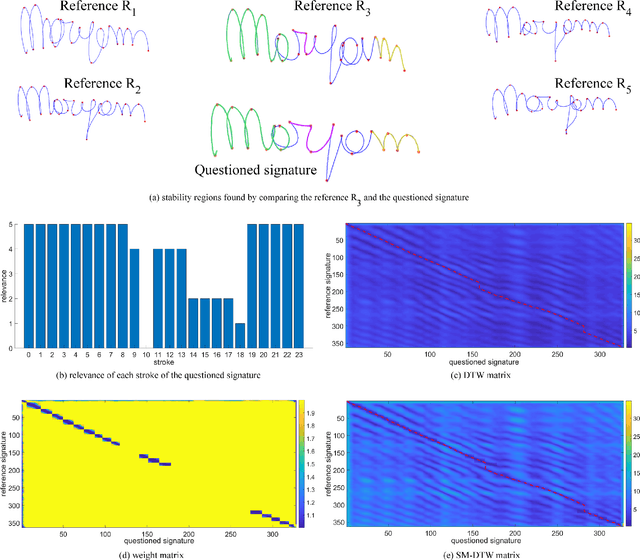

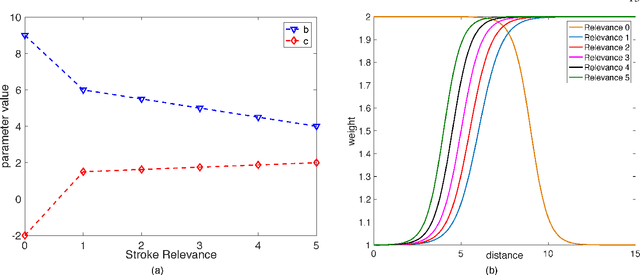
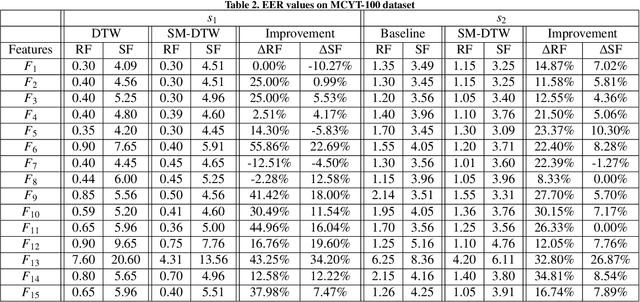
Building upon findings in computational model of handwriting learning and execution, we introduce the concept of stability to explain the difference between the actual movements performed during multiple execution of the subject's signature, and conjecture that the most stable parts of the signature should play a paramount role in evaluating the similarity between a questioned signature and the reference ones during signature verification. We then introduce the Stability Modulated Dynamic Time Warping algorithm for incorporating the stability regions, i.e. the most similar parts between two signatures, into the distance measure between a pair of signatures computed by the Dynamic Time Warping for signature verification. Experiments were conducted on two datasets largely adopted for performance evaluation. Experimental results show that the proposed algorithm improves the performance of the baseline system and compares favourably with other top performing signature verification systems.
Temporal evolution in synthetic handwriting
Jan 27, 2024New methods for generating synthetic handwriting images for biometric applications have recently been developed. The temporal evolution of handwriting from childhood to adulthood is usually left unexplored in these works. This paper proposes a novel methodology for including temporal evolution in a handwriting synthesizer by means of simplifying the text trajectory plan and handwriting dynamics. This is achieved through a tailored version of the kinematic theory of rapid human movements and the neuromotor inspired handwriting synthesizer. The realism of the proposed method has been evaluated by comparing the temporal evolution of real and synthetic samples both quantitatively and subjectively. The quantitative test is based on a visual perception algorithm that compares the letter variability and the number of strokes in the real and synthetic handwriting produced at different ages. In the subjective test, 30 people are asked to evaluate the perceived realism of the evolution of the synthetic handwriting.
* Published in Pattern Recognition
I Can't Believe It's Not Better: In-air Movement For Alzheimer Handwriting Synthetic Generation
Dec 08, 2023During recent years, there here has been a boom in terms of deep learning use for handwriting analysis and recognition. One main application for handwriting analysis is early detection and diagnosis in the health field. Unfortunately, most real case problems still suffer a scarcity of data, which makes difficult the use of deep learning-based models. To alleviate this problem, some works resort to synthetic data generation. Lately, more works are directed towards guided data synthetic generation, a generation that uses the domain and data knowledge to generate realistic data that can be useful to train deep learning models. In this work, we combine the domain knowledge about the Alzheimer's disease for handwriting and use it for a more guided data generation. Concretely, we have explored the use of in-air movements for synthetic data generation.
A Few Shot Multi-Representation Approach for N-gram Spotting in Historical Manuscripts
Sep 21, 2022
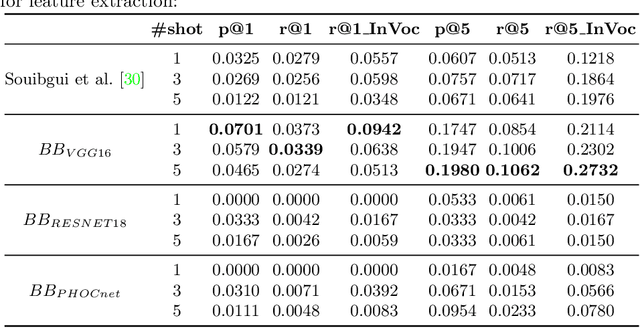

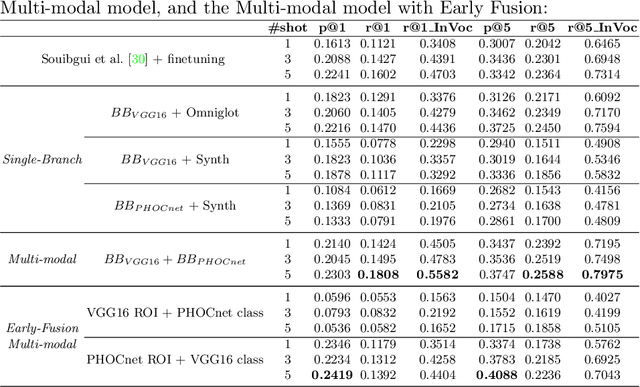
Despite recent advances in automatic text recognition, the performance remains moderate when it comes to historical manuscripts. This is mainly because of the scarcity of available labelled data to train the data-hungry Handwritten Text Recognition (HTR) models. The Keyword Spotting System (KWS) provides a valid alternative to HTR due to the reduction in error rate, but it is usually limited to a closed reference vocabulary. In this paper, we propose a few-shot learning paradigm for spotting sequences of a few characters (N-gram) that requires a small amount of labelled training data. We exhibit that recognition of important n-grams could reduce the system's dependency on vocabulary. In this case, an out-of-vocabulary (OOV) word in an input handwritten line image could be a sequence of n-grams that belong to the lexicon. An extensive experimental evaluation of our proposed multi-representation approach was carried out on a subset of Bentham's historical manuscript collections to obtain some really promising results in this direction.