 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Model OCR Training on Historical Latin Script for Out-of-the-Box Recognition and Finetuning
Jun 15, 2021

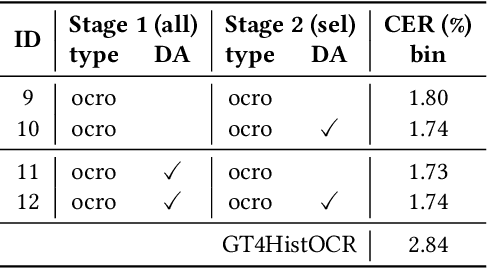
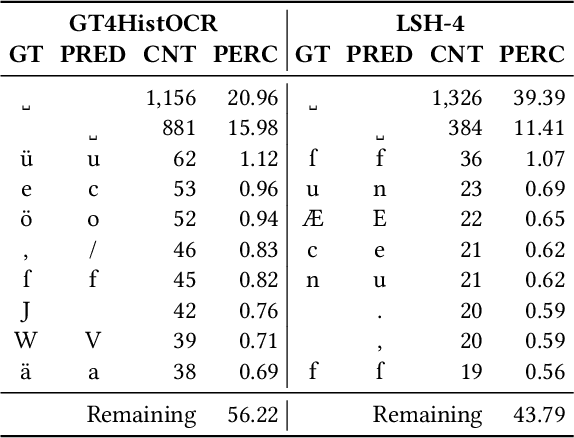
In order to apply Optical Character Recognition (OCR) to historical printings of Latin script fully automatically, we report on our efforts to construct a widely-applicable polyfont recognition model yielding text with a Character Error Rate (CER) around 2% when applied out-of-the-box. Moreover, we show how this model can be further finetuned to specific classes of printings with little manual and computational effort. The mixed or polyfont model is trained on a wide variety of materials, in terms of age (from the 15th to the 19th century), typography (various types of Fraktur and Antiqua), and languages (among others, German, Latin, and French). To optimize the results we combined established techniques of OCR training like pretraining, data augmentation, and voting. In addition, we used various preprocessing methods to enrich the training data and obtain more robust models. We also implemented a two-stage approach which first trains on all available, considerably unbalanced data and then refines the output by training on a selected more balanced subset. Evaluations on 29 previously unseen books resulted in a CER of 1.73%, outperforming a widely used standard model with a CER of 2.84% by almost 40%. Training a more specialized model for some unseen Early Modern Latin books starting from our mixed model led to a CER of 1.47%, an improvement of up to 50% compared to training from scratch and up to 30% compared to training from the aforementioned standard model. Our new mixed model is made openly available to the community.
OCR4all -- An Open-Source Tool Providing a Automatic OCR Workflow for Historical Printings
Sep 09, 2019

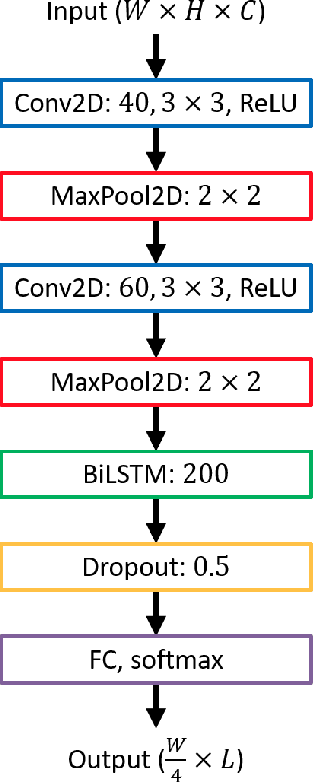
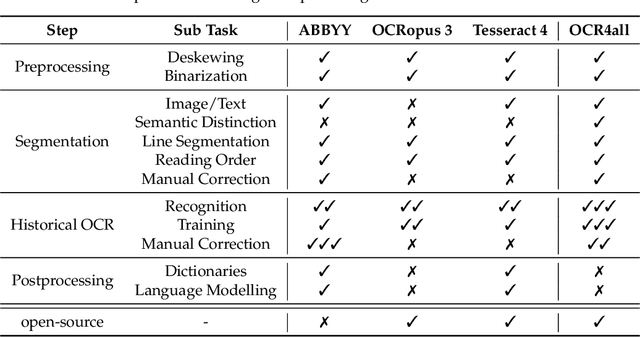
Optical Character Recognition (OCR) on historical printings is a challenging task mainly due to the complexity of the layout and the highly variant typography. Nevertheless, in the last few years great progress has been made in the area of historical OCR, resulting in several powerful open-source tools for preprocessing, layout recognition and segmentation, character recognition and post-processing. The drawback of these tools often is their limited applicability by non-technical users like humanist scholars and in particular the combined use of several tools in a workflow. In this paper we present an open-source OCR software called OCR4all, which combines state-of-the-art OCR components and continuous model training into a comprehensive workflow. A comfortable GUI allows error corrections not only in the final output, but already in early stages to minimize error propagations. Further on, extensive configuration capabilities are provided to set the degree of automation of the workflow and to make adaptations to the carefully selected default parameters for specific printings, if necessary. Experiments showed that users with minimal or no experience were able to capture the text of even the earliest printed books with manageable effort and great quality, achieving excellent character error rates (CERs) below 0.5%. The fully automated application on 19th century novels showed that OCR4all can considerably outperform the commercial state-of-the-art tool ABBYY Finereader on moderate layouts if suitably pretrained mixed OCR models are available. The architecture of OCR4all allows the easy integration (or substitution) of newly developed tools for its main components by standardized interfaces like PageXML, thus aiming at continual higher automation for historical printings.