 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR4all -- An Open-Source Tool Providing a Automatic OCR Workflow for Historical Printings
Paper and Code


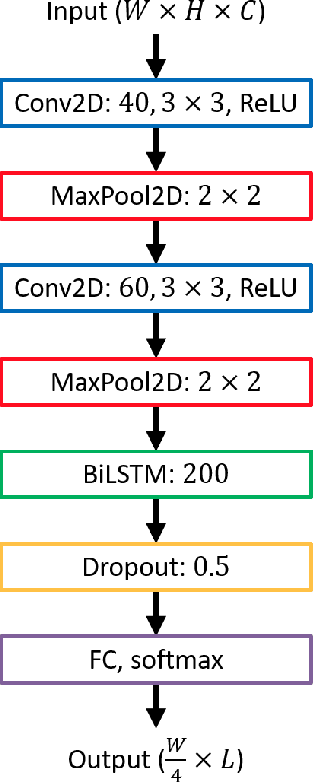
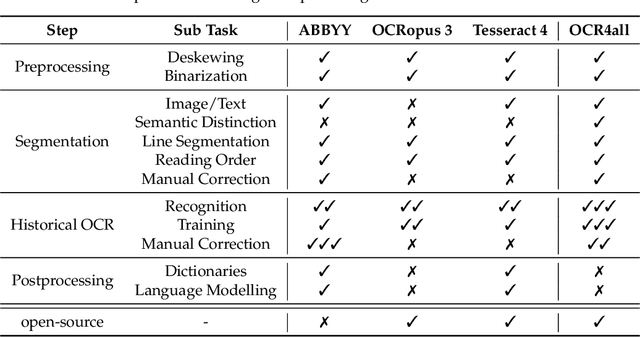
Optical Character Recognition (OCR) on historical printings is a challenging task mainly due to the complexity of the layout and the highly variant typography. Nevertheless, in the last few years great progress has been made in the area of historical OCR, resulting in several powerful open-source tools for preprocessing, layout recognition and segmentation, character recognition and post-processing. The drawback of these tools often is their limited applicability by non-technical users like humanist scholars and in particular the combined use of several tools in a workflow. In this paper we present an open-source OCR software called OCR4all, which combines state-of-the-art OCR components and continuous model training into a comprehensive workflow. A comfortable GUI allows error corrections not only in the final output, but already in early stages to minimize error propagations. Further on, extensive configuration capabilities are provided to set the degree of automation of the workflow and to make adaptations to the carefully selected default parameters for specific printings, if necessary. Experiments showed that users with minimal or no experience were able to capture the text of even the earliest printed books with manageable effort and great quality, achieving excellent character error rates (CERs) below 0.5%. The fully automated application on 19th century novels showed that OCR4all can considerably outperform the commercial state-of-the-art tool ABBYY Finereader on moderate layouts if suitably pretrained mixed OCR models are available. The architecture of OCR4all allows the easy integration (or substitution) of newly developed tools for its main components by standardized interfaces like PageXML, thus aiming at continual higher automation for historical printings.