 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalamari - A High-Performance Tensorflow-based Deep Learning Package for Optical Character Recognition
Paper and Code

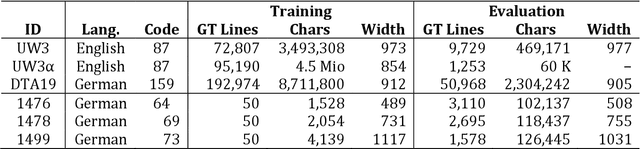

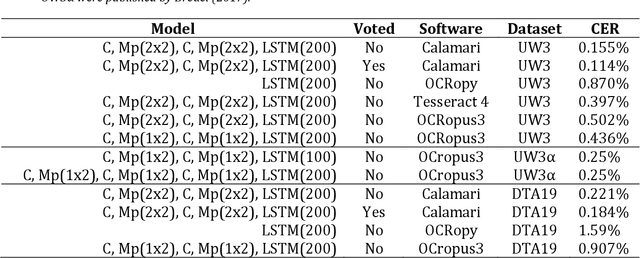
Optical Character Recognition (OCR) on contemporary and historical data is still in the focus of many researchers. Especially historical prints require book specific trained OCR models to achieve applicable results (Springmann and L\"udeling, 2016, Reul et al., 2017a). To reduce the human effort for manually annotating ground truth (GT) various techniques such as voting and pretraining have shown to be very efficient (Reul et al., 2018a, Reul et al., 2018b). Calamari is a new open source OCR line recognition software that both uses state-of-the art Deep Neural Networks (DNNs) implemented in Tensorflow and giving native support for techniques such as pretraining and voting. The customizable network architectures constructed of Convolutional Neural Networks (CNNS) and Long-ShortTerm-Memory (LSTM) layers are trained by the so-called Connectionist Temporal Classification (CTC) algorithm of Graves et al. (2006). Optional usage of a GPU drastically reduces the computation times for both training and prediction. We use two different datasets to compare the performance of Calamari to OCRopy, OCRopus3, and Tesseract 4. Calamari reaches a Character Error Rate (CER) of 0.11% on the UW3 dataset written in modern English and 0.18% on the DTA19 dataset written in German Fraktur, which considerably outperforms the results of the existing softwares.