 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for OCRopus Model Training on Early Printed Books
Paper and Code
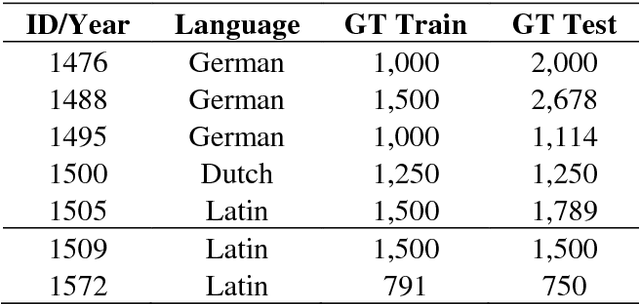

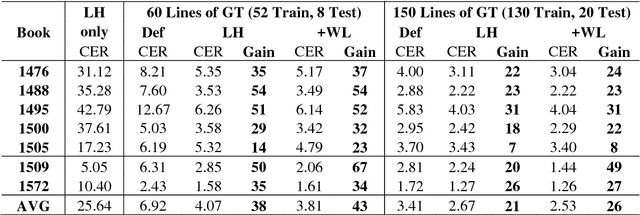
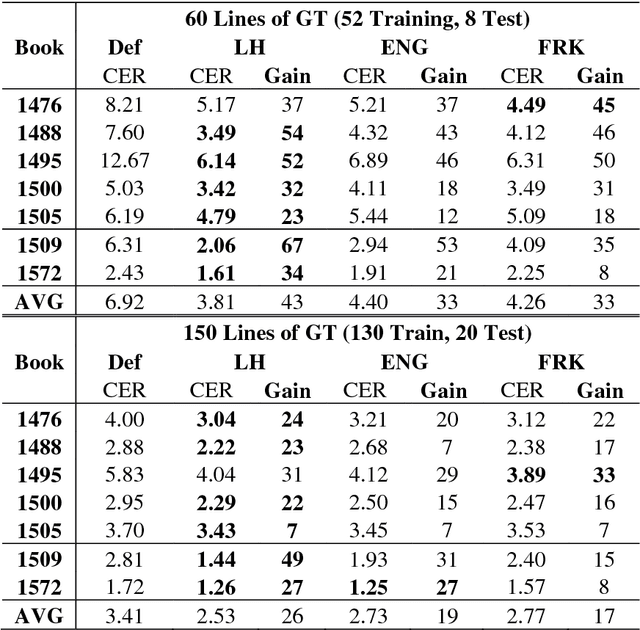
A method is presented that significantly reduces the character error rates for OCR text obtained from OCRopus models trained on early printed books when only small amounts of diplomatic transcriptions are available. This is achieved by building from already existing models during training instead of starting from scratch. To overcome the discrepancies between the set of characters of the pretrained model and the additional ground truth the OCRopus code is adapted to allow for alphabet expansion or reduction. The character set is now capable of flexibly adding and deleting characters from the pretrained alphabet when an existing model is loaded. For our experiments we use a self-trained mixed model on early Latin prints and the two standard OCRopus models on modern English and German Fraktur texts. The evaluation on seven early printed books showed that training from the Latin mixed model reduces the average amount of errors by 43% and 26%, respectively compared to training from scratch with 60 and 150 lines of ground truth, respectively. Furthermore, it is shown that even building from mixed models trained on data unrelated to the newly added training and test data can lead to significantly improved recognition results.